Evaluation framework delivers consistent performance and reliability for travel assistant
Our client already had a generative Al-powered travel assistant to assist with bookings, flights and itineraries. They wanted to improve the customer experience by enhancing the reliability and trustworthiness of the travel assistant.
We developed a modular evaluation framework for our client that can be integrated into any generative AI solution. Our framework covers various evaluation metrics, such as reliability, safety and security, relevance, and privacy.
The enhanced travel assistant automates the entire travel planning process, from creating personalized itineraries to conducting real-time internet searches for the availability, fares of flights and hotels. Given the complexities of handling such tasks with a probabilistic model like a Large Language Model, it’s critical that the responses are accurate, relevant, and safe. The evaluation framework was specifically designed to assess these aspects, and to continuously score the quality of the responses generated by the assistant.
In this blog, we’ll dive into the details on how this evaluation framework improved the reliability of its travel assistant with a GenAl-powered solution developed by Infogain.
Intelligent Travel Assistant
Our client’s travel assistant uses automation to simplify the travel journey of key tasks such as:
- Generating detailed and personalized itineraries based on user inputs.
- Identifying and recommending flights that align with the user’s preferences and travel constraints.
- Suggesting hotels and facilitating bookings based on real-time availability, user preferences, and reviews.
- Conducting live searches on the internet for current information on flights, hotels, destinations and other travel details, thereby providing up-to-date results to the users.
The primary challenge was to ensure that the responses generated by Al are accurate and trustworthy across various user requests.
4 key metrics for evaluation
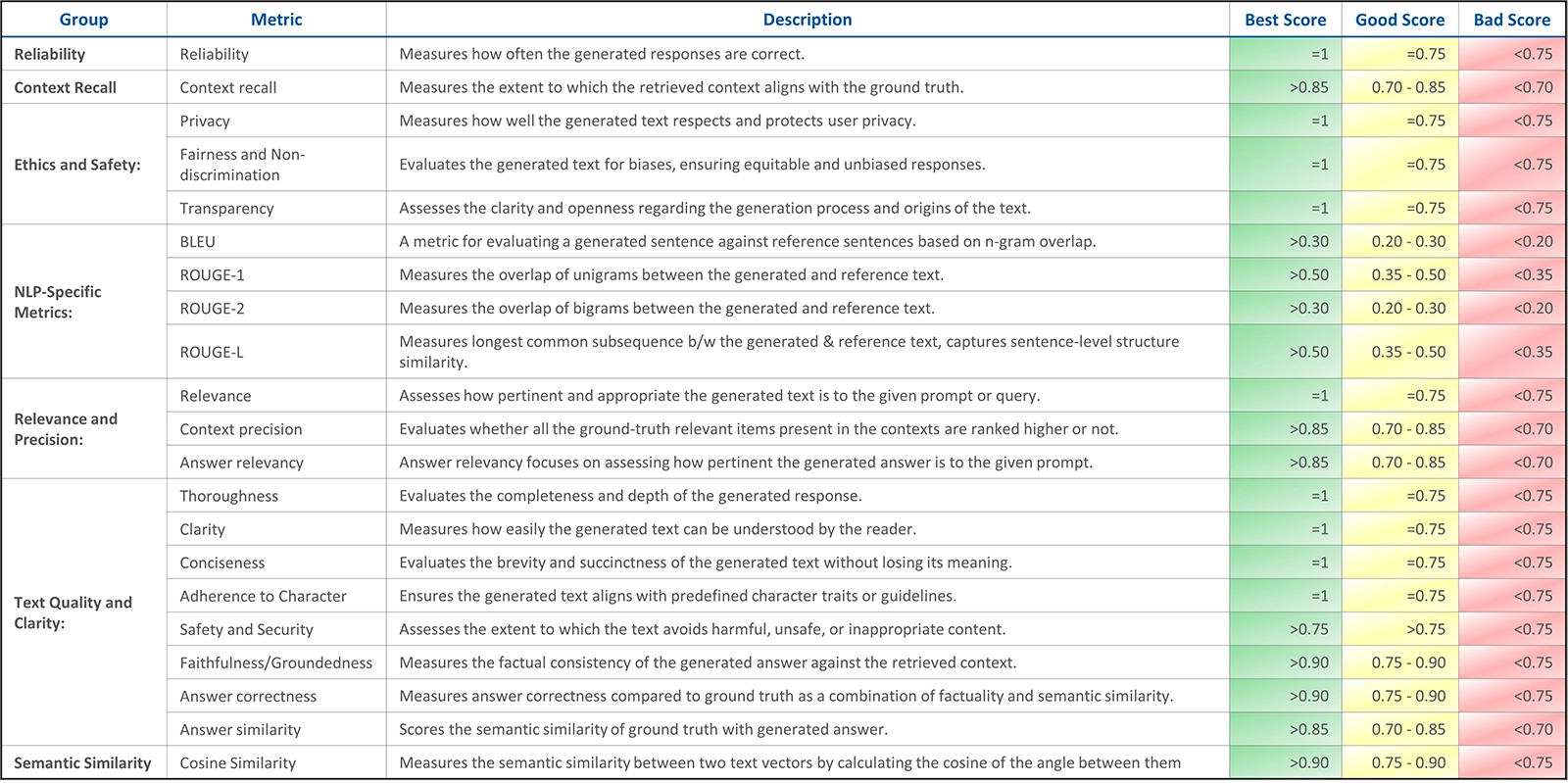
Our framework evaluates the travel assistant’s responses on four critical dimensions to guarantee high-quality outputs:
Reliability is measured by the accuracy and correctness of the generated responses. The assistant must deliver precise and factual results, such as recommending flights or hotels based on real-time data and user preferences, not based on some static data or pre-trained model.
Safety & Security ensures that responses are free from harmful, unsafe, or inappropriate content. In the context of travel, this includes verifying that recommendations do not pose any safety risks or lead to unethical outcomes.
Relevance is assessed on how well the generated response aligns with the user’s query. For instance, if a user searches for hotels within a certain budget, the assistant must provide options that fit in those criteria accurately.
Privacy of the user is safeguarded by ensuring no sensitive information is shared or leaked in the responses. This metric is particularly critical when the solution interacts with real-time internet searches or user-specific travel data.
Seamless integration in production environment
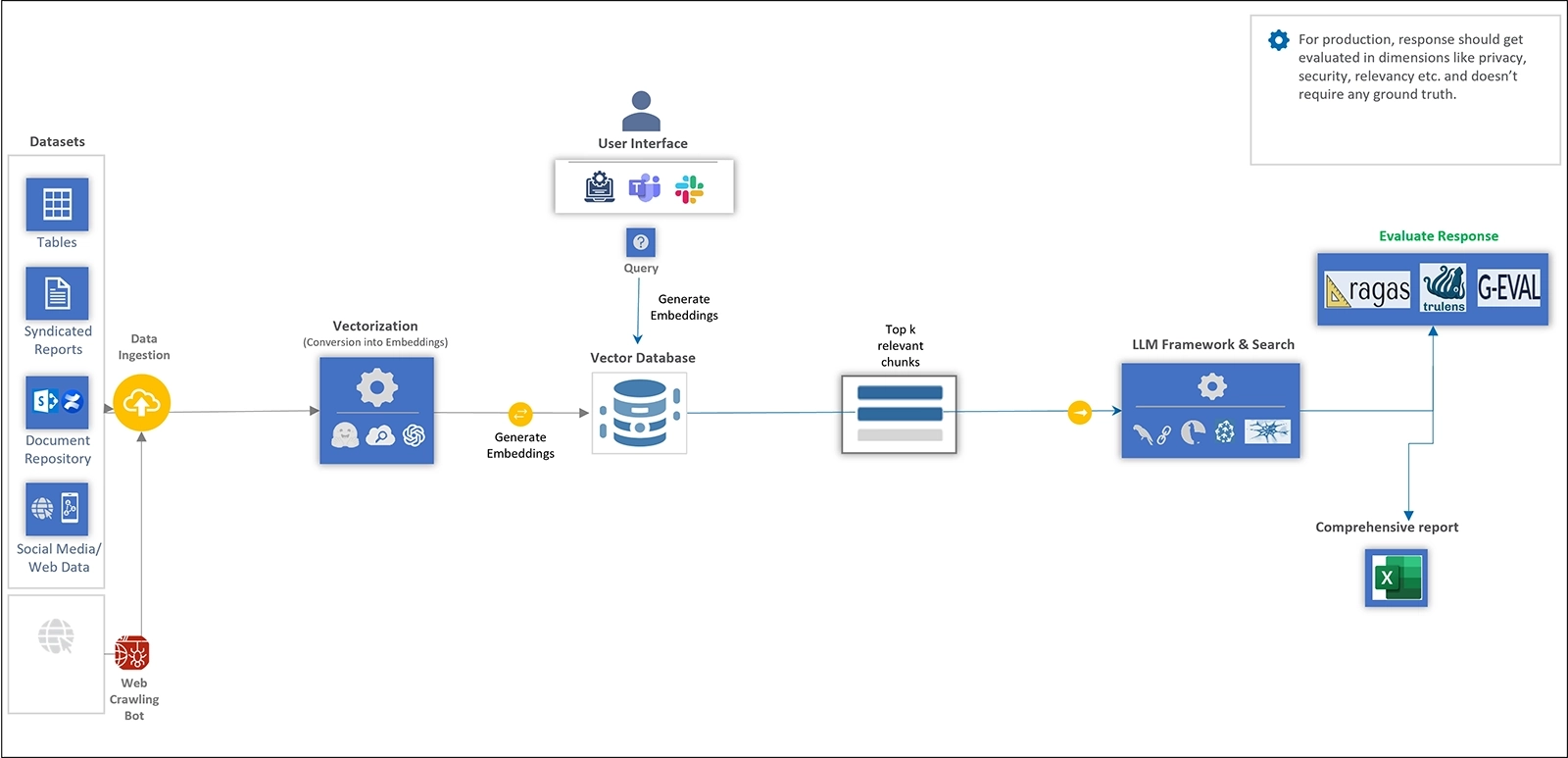
The evaluation framework’s architecture is designed to function seamlessly in the background, continuously assessing responses during real-time user interactions. Whether users are creating itineraries or searching for flights and hotels, each response is automatically evaluated across the four key metrics. The system then generates a comprehensive score for every response, providing valuable insights into the trustworthiness of the LLM’s outputs.
Figure 1: Architecture of evaluation module in production environment
Sample evaluation results
Below is an example of the response generated by the travel assistant, evaluated across reliability, safety & security, relevance, and privacy. These scores offer clear insights into the quality of the system’s outputs, ensuring consistent performance in real-world travel scenarios.
Figure 2: Sample response
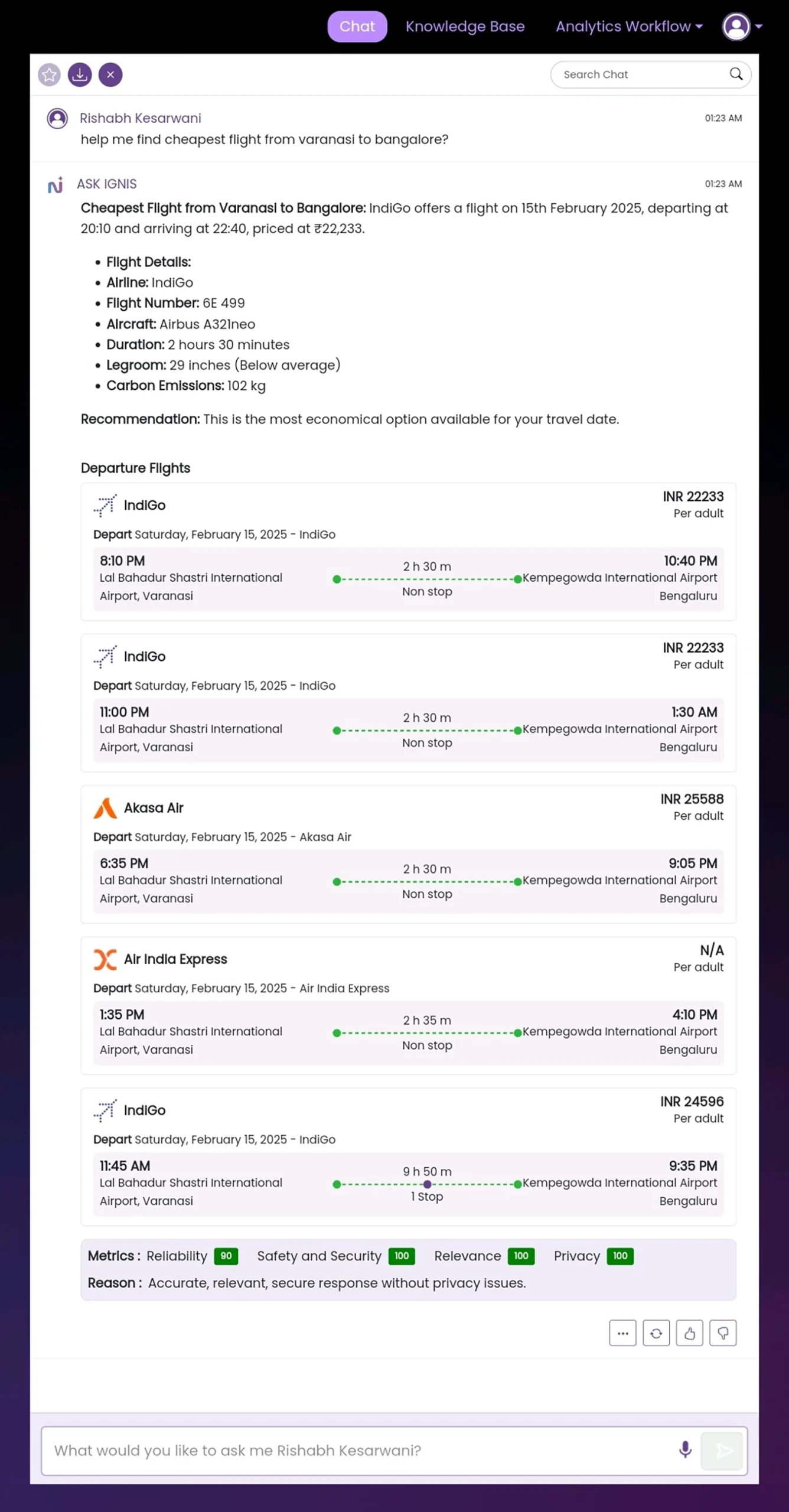
Figure 3: Metrics description for Infogain’s GenAI evaluation module
Conclusion
The integration of this evaluation framework ensures that the GenAl-powered travel assistant simplifies travel planning in a reliable, safe, and privacy-conscious manner. By assessing the generated responses across the key metrics, the system continuously refines itself, offering users an experience that they can trust, whether they’re searching for flights, booking hotels, or building travel itineraries. The framework ensures that the solution meets the highest standards of accuracy, relevance, and security, making it an indispensable tool for modern travelers.
Turning ‘Talk’ into Action through GenAI-powered Call Analytics
Organizations depend on call analytics software to understand their customers’ preferences, enhance customer services, conduct more efficient operations, comply with legal and regulatory requirements, refine training, and more. In an era where customer interactions shape the brand narrative, the time has arrived to look beyond the transcripts and leverage Generative Al to mine actionable insights from call recordings.
Recently, we developed a prototype for an American data analytics, software, and consumer intelligence company that demonstrates how advanced Al models can go beyond traditional analytics, offering an unprecedented depth of understanding in customer-agent interactions. Our innovative approach elevates customer service from reactive troubleshooting to proactive engagement. By identifying systematic issues early on, agents are empowered with precise feedback, ultimately enhancing the overall customer experience.
Enhancing Call Insights with GenAI
Our prototype processes entire call recordings, extracting insights like customer sentiment, agent performance, call summaries, issue status, and product mentions. It’s highly scalable, has integration capabilities, and automation such as storing output in a database, creating dashboards and chatbots. Its advanced capabilities include:
Sentiment Analysis
Beyond basic sentiment classification, the model scores emotions on a scale of 1 to 10, revealing subtle shifts in mood throughout the call. For example, in a call involving a technical issue with a pin pad, the customer’s initial frustration was noted, but the sentiment improved significantly once the problem was resolved.
Agent Performance Metrics
Each call is assessed on communication clarity, patience, and problem-solving effectiveness. This granular evaluation helps to identify top performers including specific areas for each agent to improve, such as clarifying initial instructions to avoid repeated steps.
Detailed Call Summaries
Summarizations capture the essence of each interaction, detailing the problem, steps taken, and final resolution. This concise report is invaluable for stakeholders who need quick insights without diving into full call recordings.
Outcome Tracking and Recommendations
The model provides actionable recommendations to both agents and customers, enhancing future interactions. In the example of the pin pad issue, a suggestion was made to double-check cable connections to prevent similar problems.
![]()
![]()
Streamlining Analytics through Data Automation and Integration
After insights are generated, they are pushed automatically into databases or Excel sheets, making data storage and accessibility seamless. This opens the door to a range of output formats tailored to specific needs:
Using platforms like Zoho, we created dashboards that visualize agent performance, sentiment trends, and issue resolution rates. These visual representations help stakeholders quickly grasp the broader picture and make data-driven decisions.
Our IGNIS GenAI bot, integrated with the prototype, allows its users to query the data directly. Questions like the following are answered in real time, transforming static data into dynamic and interactive insights:
- What is the average duration of calls? Additionally, could you provide information on the shortest and longest calls recorded?
- Could you provide details regarding call ID 1001V?
- Who is the top-performing agent, and what factors contribute to their success?
- Are there any specific calls that warrant concern? If so, please explain the reasons.
- Can you summarize the overall sentiment expressed across all calls?
The system can send curated reports via email, highlighting key metrics, emerging issues, and agent performance summaries. These reports keep stakeholders updated without requiring manual data extraction or analysis.
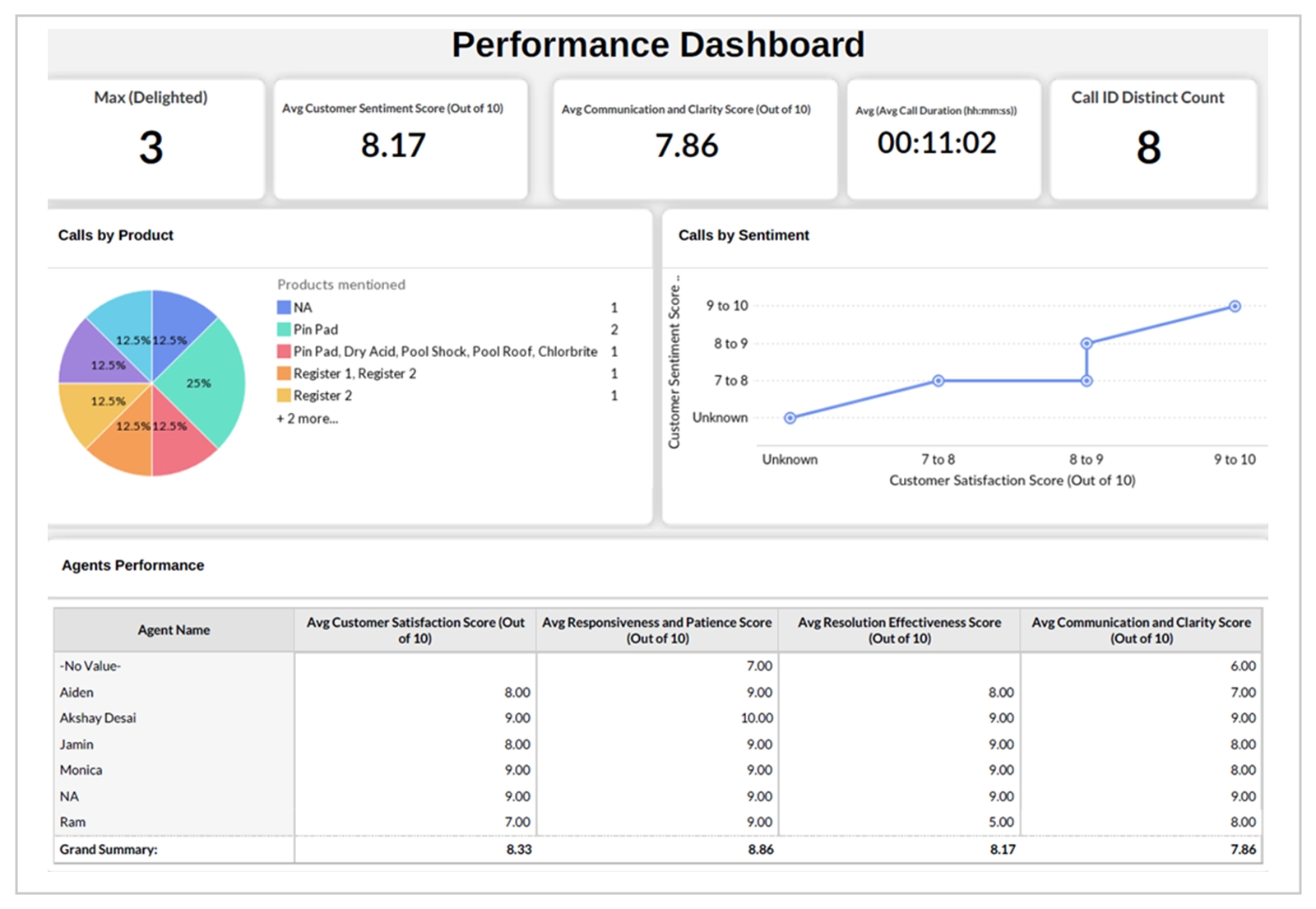
Scalability and Future Enhancements
Our prototype currently utilizes Python packages and GPT-4 Turbo API, and will scale with future advancements, including the anticipated GPT-4o’s audio capabilities. Once available, these enhancements will enable even deeper analysis of vocal tone, pacing, and more nuanced sentiment detection. The entire process-from data collection to insight generation-can be fully automated, scheduled to run at regular intervals to keep analytics fresh and relevant.
Want a demo? Connect with Team IGNIS to learn more.
Infogain’s approach to Responsible AI focuses on embedding ethical practices into every stage of AI development and deployment. Our AI/ML solutions are built to be fair, transparent, secure, and inclusive, ensuring that they serve the best interests of both our clients and society.
By following these guidelines, enterprises can harness the power of AI responsibly and deliver cutting-edge solutions that align with ethical principles and customer expectations. By prioritizing privacy, fairness, transparency, and accountability, we ensure that Infogain’s AI solutions solve complex business problems and contribute positively to the digital landscape. As AI continues to reshape industries, Responsible AI is a key enabler for long-term success and societal trust in technology.
Our Responsible AI Framework document details our best practices for implementing AI solutions across enterprises. Please download to read more.
The Four Cs of GenAI offers a structured approach to exploring the capabilities and limitations of generative technologies. Choice, Control, Calibration, and Cost form the compass. They are pivotal for translating GenAI’s potential into tangible benefits across diverse industries. These pillars provide a framework to harness generative technologies responsibly and effectively, guiding organizations across industries toward innovation while addressing challenges.
As the AI landscape evolves, embracing these pillars will be essential for organizations aiming to harness GenAI’s true power. These elements facilitate effective deployment and mitigate risks, ensuring that AI advancements are both responsible and revolutionary.
Read the Whitepaper to know more.
Azure Prompt Flow for Iterative Evolution of Prompts
Large Language Models (LLMs) are trained on internet content that is inherently probabilistic, so despite being able to produce text that is easy to believe, that text can also be incorrect, unethical, and/or prejudiced. Also, their output can vary each time, even if the inputs remain unchanged.
These errors can cause reputational or even financial damage to brands that publish it, so those brands must constantly evaluate their outputs for quality, accuracy, and slant.
There are several methods for testing output. The best for a given case depends on the case itself. At Infogain, when we need to evaluate prompt effectiveness and response quality, we use Azure Prompt Flow.
Evaluation flows can take required inputs and produce corresponding outputs, which are often the scores or metrics.
The concepts of evaluation flows differ from standard flows in the authoring experience and how they’re used. Special features of evaluation flows include:
- They usually run after the run to be tested by receiving its outputs. They use the outputs to calculate the scores and metrics. The outputs of an evaluation flow are the results that measure the performance of the flow being tested.
- They may have an aggregation node that calculates the overall performance of the flow being tested over the test dataset.
As AI applications driven by LLMs gain momentum worldwide, Azure Machine Learning Prompt Flow offers a seamless solution for the development cycle from prototyping to deployment. It empowers you to:
- Visualize and Execute: Design and execute workflows by linking LLMs, prompts, and Python tools in a user-friendly, visual interface.
- Collaborate and Iterate: Easily debug, share, and refine your flows with collaborative team features, ensuring continuous improvement.
- Test at Scale: Develop multiple prompt variants and evaluate their effectiveness through large-scale testing.
- Deploy with Confidence: Launch a real-time endpoint that maximizes the potential of LLMs for your application.
We believe that Azure Machine Learning Prompt Flow is an ideal solution for developers who need an intuitive and powerful tool to streamline LLM-based AI projects.
LLM-based application development lifecycle
Azure Machine Learning Prompt Flow streamlines AI application development through four main stages:
- Initialization: Identify the business use case, collect sample data, build a basic prompt, and develop an extended flow.
- Experimentation: Run the flow on sample data, evaluate and modify as needed, and iterate until satisfactory results are achieved.
- Evaluation & Refinement: Test the flow on larger datasets, evaluate performance, refine as necessary, and proceed if criteria are met.
- Production: Optimize the flow, deploy and monitor in a production environment, gather feedback, and iterate for improvements.
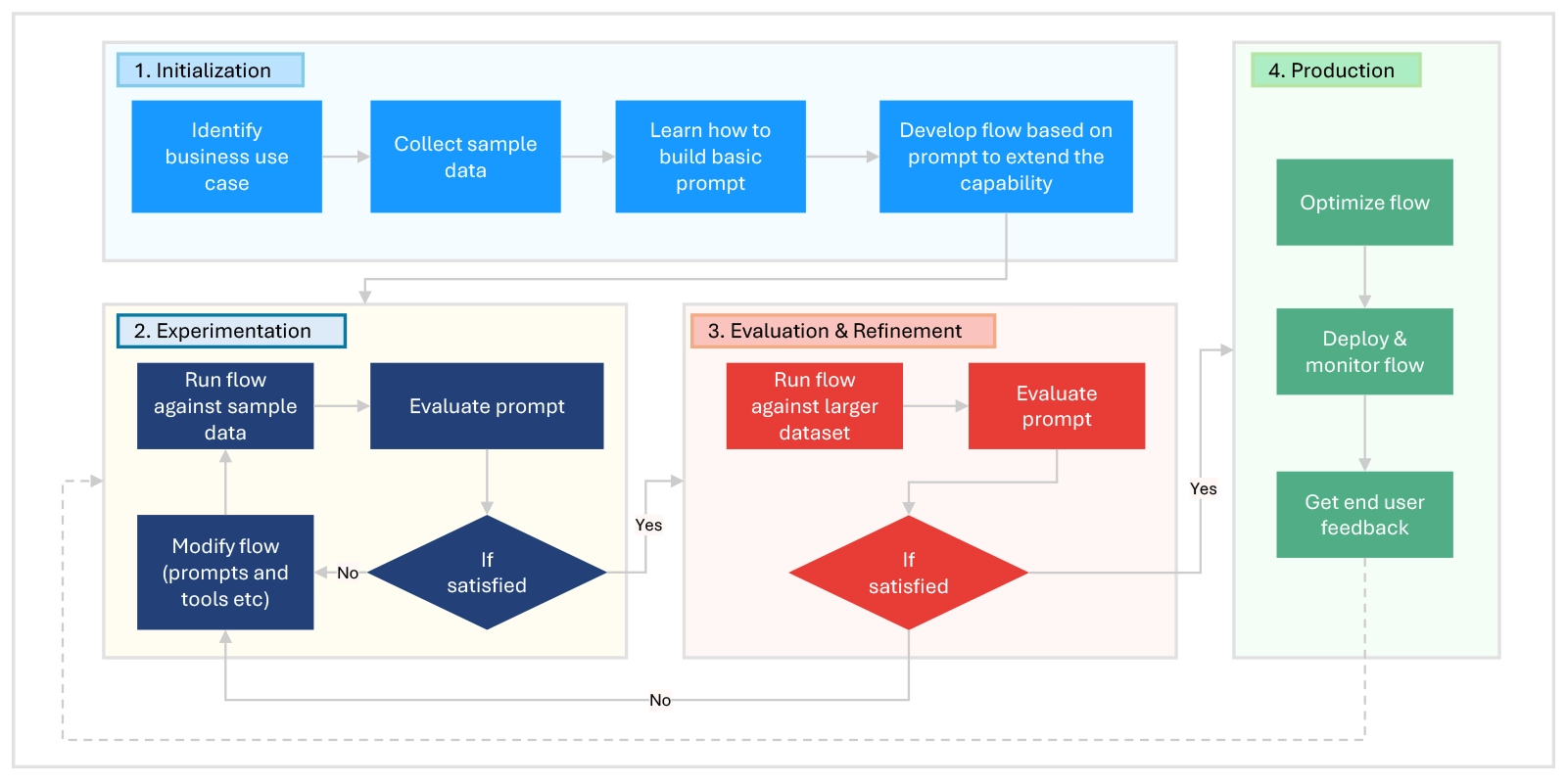
Figure 1: Prompt Flow Lifecycle
Example:
This flow demonstrates the application of Q&A using GPT, enhanced by incorporating information from Wikipedia to make the answer more grounded. This process involves searching for a relevant Wikipedia link and extracting its page contents. The Wikipedia contents serve as an augmented prompt for the GPT chat API to generate a response.
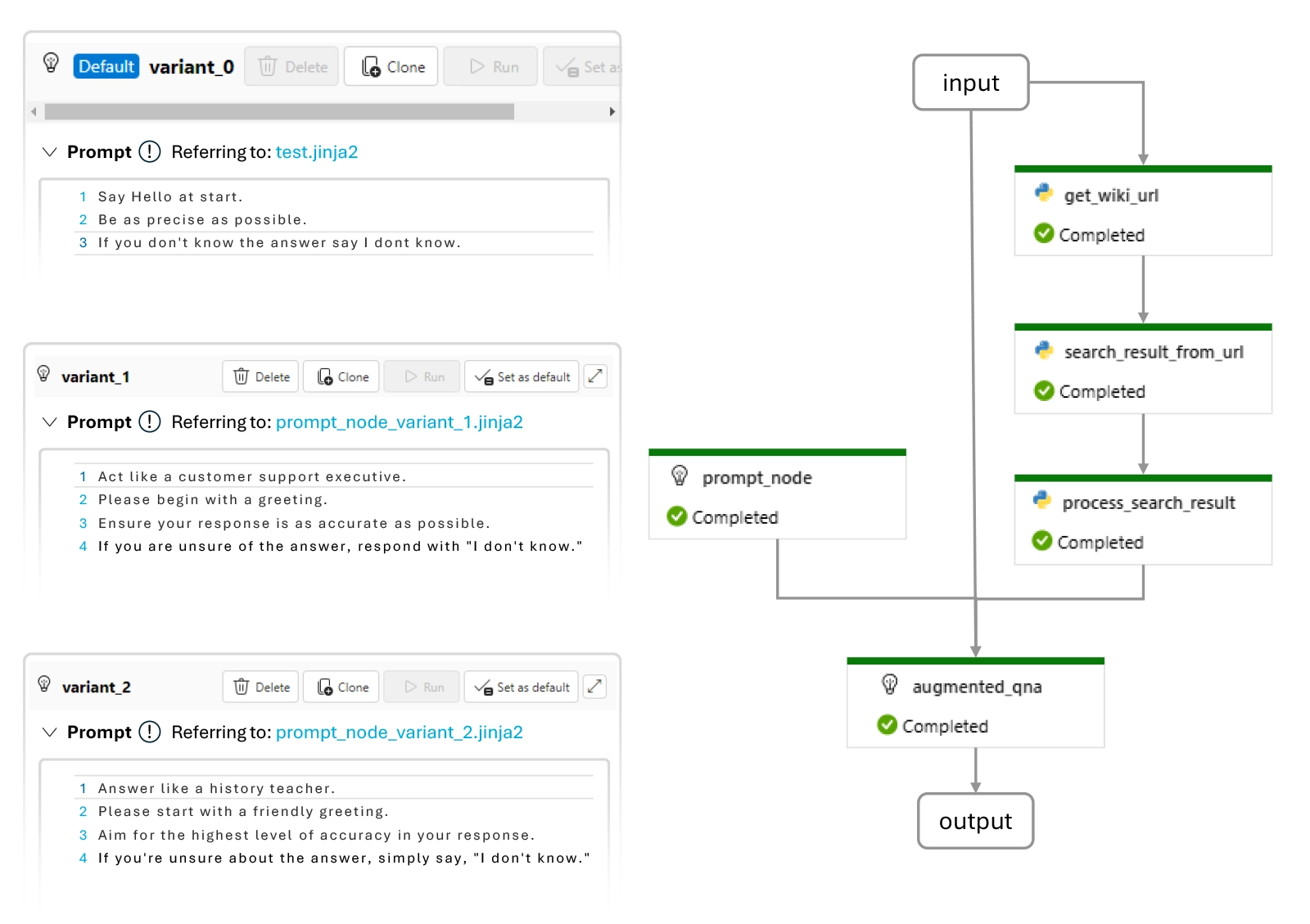
Figure 2: AskWiki Flowchart and prompt variants
Figure 2 illustrates the steps we took to link inputs to various processing stages and producing the outputs.
We utilized Azure Prompt Flow’s “Ask Wiki” template and devised three distinct prompt variations for iterative testing. Each variant can be adjusted through prompt updates and fine-tuned using parameters such as temperature and deployment models within the Language Model (LLM). However, in this example, our emphasis has been solely on filtering prompts. This approach facilitated comparisons across predefined metrics like Coherence, AdaSimilarity, Fluency, and F1 score, enabling efficient development and enhancement of robust AI applications.
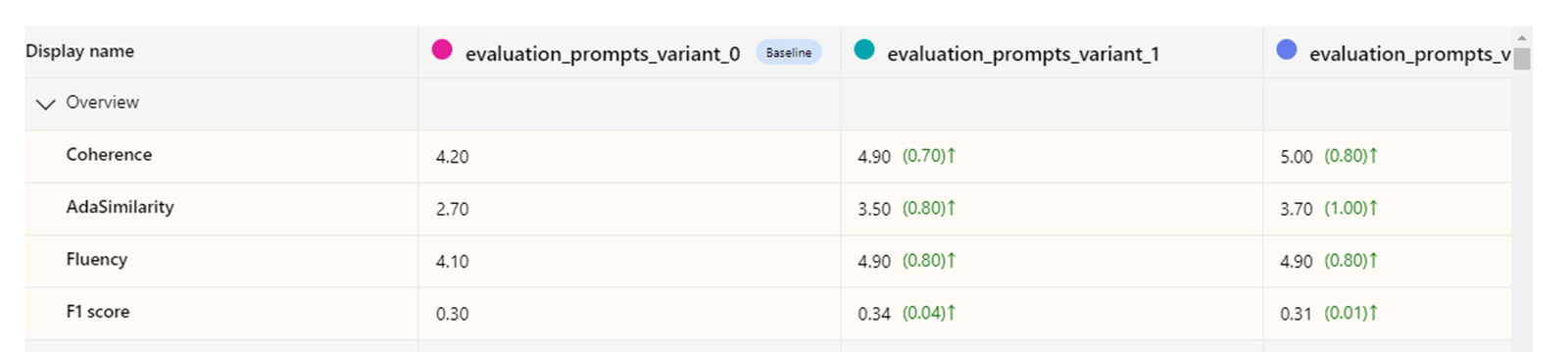
Figure 3: Output Comparison
Figure 3 shows our iterative process beginning with Variant 0, which initially yielded unsatisfactory results. Learning from this, we refined the prompts to create Variant 1, which showed incremental improvement. Building on these insights, Variant 2 was developed, exhibiting further enhancements over Variant 1. This iterative cycle involved continuous prompt updates and re-evaluation with diverse sets of Q&A data.
Through this iterative refinement and evaluation process, we aimed to identify and deploy the most effective prompts for our application. This optimized performance metrics and ensured that our AI application operates at a high standard, meeting the demands of complex user queries with precision and reliability. Each iteration brought us closer to achieving optimal performance, reflecting our commitment to excellence in AI-driven solutions.
Every business wants to leverage the actionable insights that lie hidden in their data.
This need spans organizations, from medium scale companies to giant firms. At Infogain, we encountered a similar situation with our client, a huge software firm. The firm supports 13 key products on sites that include over 10,000 web pages. These sites drive and sustain a significant portion of digital revenue and billions of customers visit them annually, so the marketing, content, and publishing demands for an operation of this size are massive.
The firm wanted to leverage its data to improve this digital presence, but their content operations had significant problems, including:
- Information overload
- Data siloing
- Non-actionable insights
- Lack of data lineage
- No single source to consume insights
Clearly, it needed a modern AI-enabled holistic content ops solution.
To mitigate and resolve these challenges. Our team implemented a GenAI-powered self-serve analytics solution, aimed at addressing these challenges and enhancing the data insights process.
The data leveraged for this solution is unstructured in nature which included:
- Performance data reports from Adobe Analytics, captured across various metrics like visits, conversions, and sign-ups.
- Existing dashboards, reports, and data sheets that provide granular insights into product performance.
- Azure research reports and other PDF documents relevant to performance analytics.
To leverage this unstructured data, we adopted a sophisticated multi-agentic retrieval-augmented generation (RAG) framework built on these pillars:
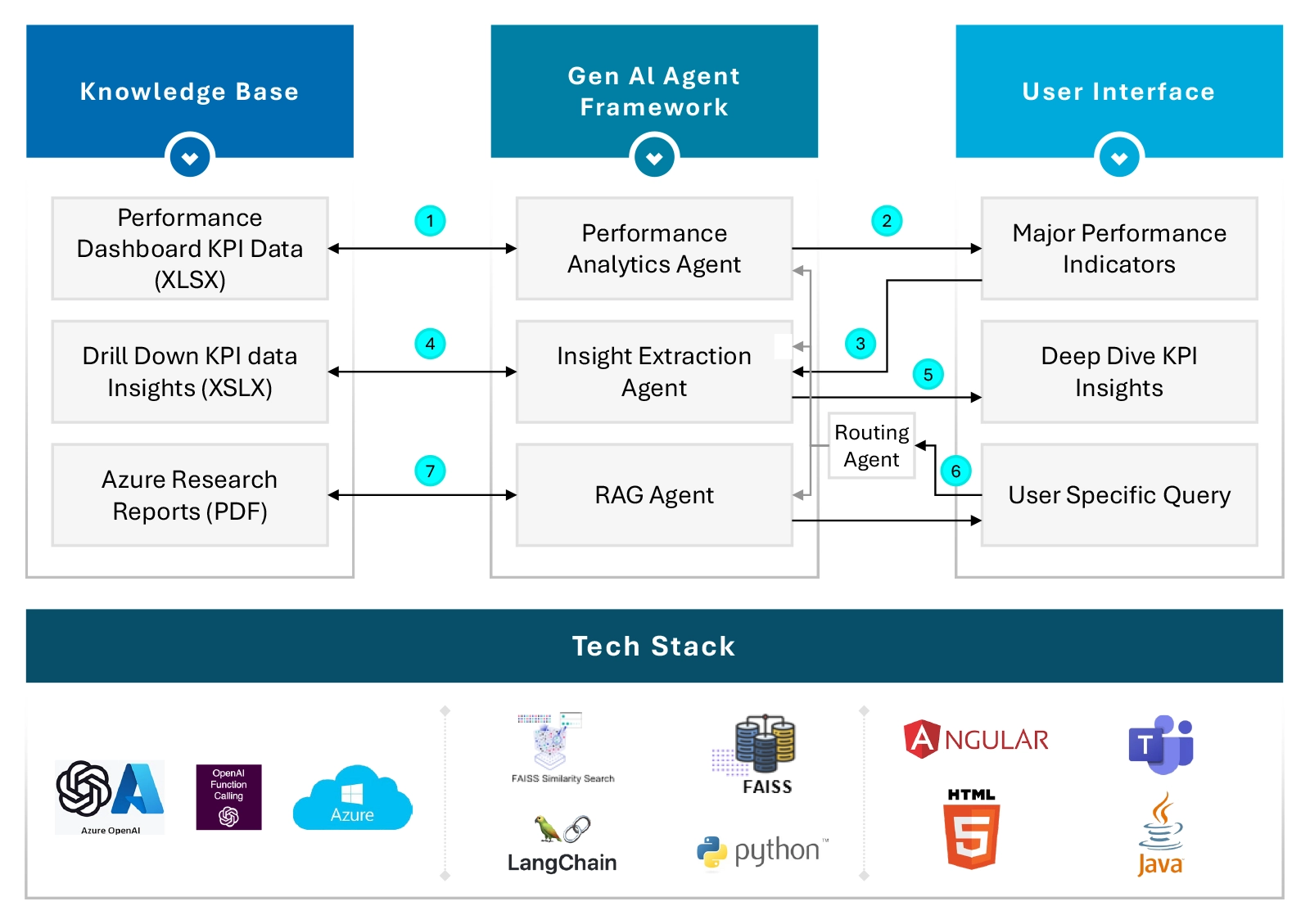
- Knowledge Base Curation: This involved aggregating all relevant data reports, including performance dashboards, detailed KPI data, and research papers.
- Agentic RAG Framework: Designed to facilitate multi-step reasoning and intelligent query routing, this framework includes several key components:
- Brain/Routing: Manages intelligent routing of user queries to the appropriate agents.
- Performance Analytics Agent: Provides an overall performance overview of products, offering users a comprehensive view at a glance, helping users quickly identify the alarming stage.
- Insights Extraction Agent: This agent delivers detailed responses to specific queries by offering top key insights and recommendations through reasoning. It drills down into the data to extract actionable insights, making it easier for users to understand complex information and make informed decisions.
- RAG Agent: Handles queries related to research documents and general factual questions.
This structured approach ensures that users can seamlessly navigate and extract meaningful insights from complex and unstructured data.
By leveraging the multi-agentic RAG framework, users also benefit from intelligent query handling, comprehensive performance overviews and detailed insights. This makes data-driven decision-making more accessible, efficient, and effective.
Moving Beyond a Chatbot
The self-serve analytics solution enhances traditional chatbot capabilities by incorporating advanced functionalities. Powered by GenAI, it provides a centralized platform for users to access, understand, and derive insights from complex reports. Key components include:
- Signals
- Function: Sends alerts to the team based on critical priorities.
- Purpose: Ensures the team is promptly informed about high-priority issues, enabling immediate action and response.
- Comprehension
- Function: Provides deep dive analysis on the signals to identify potential root causes.
- Purpose: Goes beyond simple alerts by offering thorough analysis to understand underlying issues, facilitating more informed decision-making.
- Insights
- Function: Generates tactical data insights.
- Purpose: Delivers valuable data-driven insights that support strategic planning and operational efficiency.
- Recommendations
- Function: Offers actionable insights and suggestions to mitigate potential issues.
- Purpose: Helps address and resolve identified problems, preventing future occurrences.
The GenAI-powered self-serve analytics solution enables users to drill down into specific data points, receive recommendations, and ask real-time questions. It provides both a comprehensive overview and detailed insights into areas of interest, so data-driven decision-making becomes more accessible and efficient. By integrating these components, the self-serve Insights solution transcends the basic functionalities of a chatbot, offering a comprehensive solution for better decision making and operational management.