Our client’s team started working on a new service application. Preparation of CI/CD process for it was required. The process contained some repeatable manual steps for each new service and during maintenance. It took up to three days for this process to be completed. Infogain’s team saw opportunity for improvement.
Better quality code and optimizing costs are top priorities for software developers. Finding the right tools to streamline projects can be a game-changer when using C++. Conan, a package manager, enhances the development, build, and deployment process. It also helps achieve optimal results and saves time.
Let’s discuss how this tool can be an asset for software developers.
The package manager as an important tool
In recent years, C++ has experienced significant growth and dynamic development. Beyond periodic language standard updates and improvements to the Standard Template Library (STL), the C++ ecosystem has seen the emergence of powerful development tools dedicated to enhancing code quality. These tools include static code analyzers, code sanitizers, and performance analyzers.
One such important tool is the package manager. While package managers have long been a staple in other programming languages, they have been underutilized in C++. Notable options, such as NuGet, Vcpkg, and Conan, offer solutions for managing dependencies and simplifying library preparation during deployment.
Conan has gained recognition as a standard choice among developers for its efficiency and versatility. Conan’s availability on multiple platforms, compatibility with any build systems, and numerous external libraries make it a compelling option. If you want to know more, please visit this page https://conan.io
Benefits of using Conan in the CI/CD process
When establishing the CI/CD process for a new service, there are inevitably some inefficiencies and areas for improvement. Creating a new Docker image for each new service and the manual installation of service-specific dependencies by developers was the norm. These images also required ongoing maintenance as new dependencies emerge in the future.
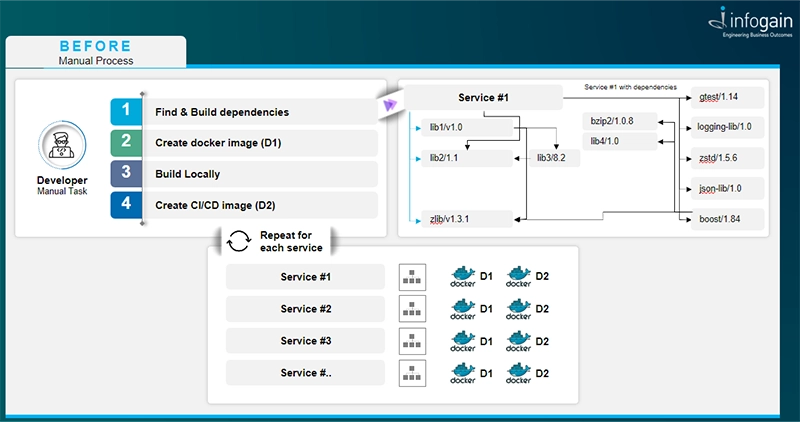
Instead of maintaining individual Docker images for each service, a unified Docker image for C++ projects, complete with the Conan application, is more advantageous. This image, when employed during the Jenkins job execution, would fetch the project’s specific dependencies from a conanfile.py located within the project repository.
This solution fosters standardization across different projects’ CI processes, enhancing consistency and efficiency.
When a developer using Conan in the CI/CD process can count on the following benefits:
- No need to prepare Docker image for each new service, we have one able to build them all.
- Less time preparing and maintaining CI/CD processes.
- Automatic resolve and download external dependencies.
- Automation and simplification of processes of preparing dependencies for deployment.
- Faster transition to new operating system versions.
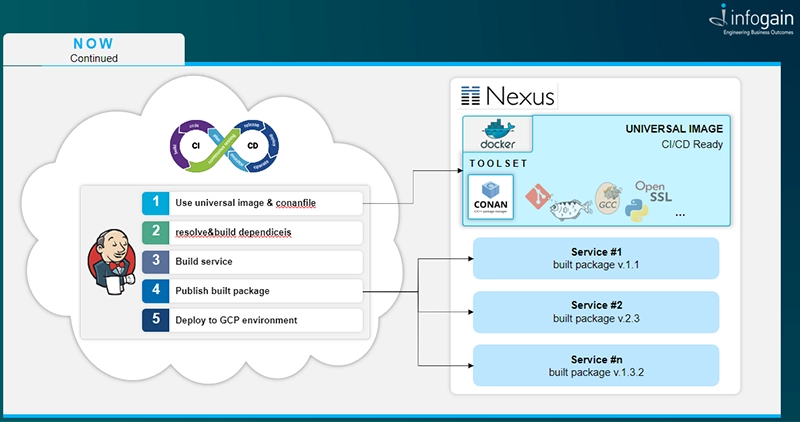
How Conan can improve your development environment preparation
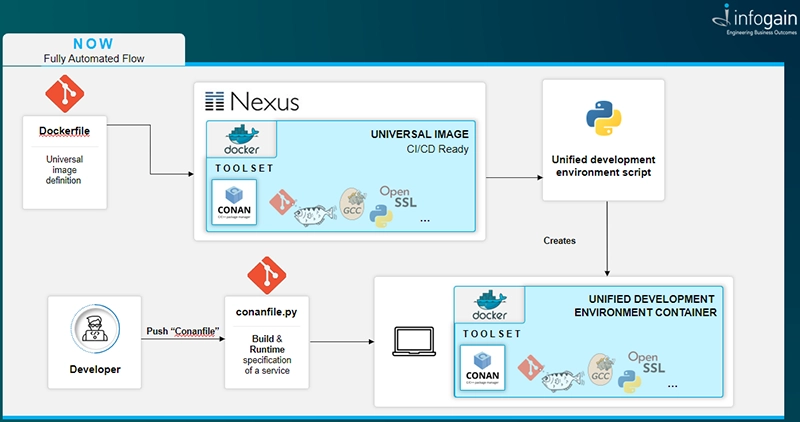
The same base Docker image with Conan used in CI/CD process can be used by a Python script, which will automatically prepare local development environment on developer PC. It just automatically installs and starts the Docker service on local PC, download base Docker image, install a ssh key to access the git repository, also install some tools which will help with development and run a Local Development Environment container.
The developer needs just to download a C++ project from git repository and call command conan build. Thanks to the specification file placed in repository, Conan will automatically provide all required dependencies for our environment and trigger compilation of your project.
Now we have one common development environment in which we can code any C++ project that uses Conan instead of preparing a new one for each new project.
So, thanks to this we have:
Cost savings
Developers can work without a virtual machine from a cloud such as Google Cloud Platform (GCP). While this may not be feasible for big projects due to computing limitations, it is invaluable for small and mid-sized projects. Implementing this solution can translate into cost savings for the company.
Effortless environment setup
Just run the Python script.
Saving time
The Python script takes care of the main tasks of setting up the work environment, allowing developers to focus on coding and development rather than dealing with environment setup intricacies.
Environment consistency and ease of use
The development environment can be employed across various C++ projects using the same build system and compiler. New images with a newer version of the compiler can be provided as required. This consistency minimizes the risk of compatibility.
Local success translates to pipeline success
When developers build a project locally, they operate in the same environment used during the CI/CD process. This alignment ensures that if a build succeeds locally, it is highly likely to succeed in the CI pipeline, providing an extra layer of confidence in the code.
Collaborative environment
All team members work in an identical environment, eliminating discrepancies and promoting better collaboration. This reduces troubleshooting, enabling the team to focus on the task.
Future opportunities
The versatility of this environment opens the door for many improvement possibilities. Adding static code analyzers like Clang-Tidy, preparing the environment for Fuzz testing, code debugging using IDEs, or staying updated with the latest compiler versions and language standards are just some of the many enhancements possible, which, in turn, can lead to higher software quality.
Integrating a package manager into your software development process offers an array of advantages, from time and cost savings to enhanced consistency and collaboration. It simplifies the development environment setup and paves the way for continuous improvements, ensuring the development process remains agile, efficient, and resilient.
Databricks continues to innovate ahead of the market, and customers are buying. In the recently concluded Databricks Data & AI Summit in San Francisco, we met with industry stalwarts, decision-makers, and influencers across industries. The energy and excitement was palpable among both customers and partners. We attended the electrifying sessions, interacted with industry leaders, and niche players, and explored how Databricks continues to innovate ahead of the market and why customers are buying from them.
Here are the key highlights from the event.
- Enterprise AI
- Databricks put a significant focus on Mosaic AI at the event. Mosaic AI is designed to enhance and simplify GenAI development, using compound AI systems as well as providing fine-tuning, evaluation, and governance tools. They are enhancing their AI capabilities for enterprises, focusing on tools like vector stores, fine-tuning, custom LLM pre-training, fully owned inference, etc. Several new features within the Mosaic AI suite were announced to support this “Enterprise AI” workflow.
- Databricks is doubling down on the core belief that scaling AI for Enterprises will require much more than integrating frontier LLM models. Enterprises will need a way to build compound AI systems and the ability to fine-tune or pre-train their models.
- Becoming an End-to-End Platform
- The new Lakeflow product was announced to assist data engineering, ingestion, and ETL.
- Databricks is further expanding its offerings to become an “end-to-end” platform for all data and AI needs. Enhanced Unity Catalog, Metrics Store, DbSQL (EDW built on Lakehouse), and more were announced.
- This strategy challenges ISVs and even competes with Hyperscalers’ native offering. Databricks thinks that they can give a better cost/performance with these offerings.
- The company also bought Tabular which enables interoperability between Databricks and the Iceberg format in Snowflake.
- “AI first” visualization
AI/BI, a new ‘AI-first’ visualization tool that will likely compete with PowerBI, Tableau, etc was announced at the event.
- Opensource
There is an emphasis on open formats and standards over closed ecosystems. Unity Catalog was open-sourced live at the keynote. This will ensure greater connectivity with Delta Sharing.
- Evolving Partner landscape
Databricks’ partner community has doubled in the last year. The partner ecosystem continues to thrive with remarkable growth in partner-certified consultants as both large IT companies as well as smaller and niche players keep coming to the fold.
In conclusion
With a 60% YoY sales growth, Databricks is projected to hit $2.4B in revenue, making it one of the largest private unicorns in the world. This clearly shows that modern clients are razor-focused on making the most of their data through intelligent solutions driven by advanced AI capabilities.
At Infogain, we have been helping our clients transform their businesses with our industry-recognized Data and AI practices. Connect with us today and let’s discuss how we can help you leapfrog to the bold new world of data and AI.
With the recent advancements in the space of Artificial Intelligence (AI) and especially generative AI, machines are being trained to think, learn, and even communicate – just like humans. Enterprises are now looking leverage this to create generative AI use cases that let them streamline, speed-up, and transform their businesses.
This is where, the importance of prompt engineering is also evolving and scaling up as it sits in the crucial space between what the human user wants and what the machines understand.
So, what exactly is prompt engineering?
Prompt engineering is all about having a conversation with a machine based on a ‘prompt’ where it will respond with relevant information and requested actions. The key essence is the crafting of the right questions to help guide the Large Language Models (LLMs) to generate the desired outcomes. Why prompt engineering is becoming crucial is the ability to harness the power of computing to get answers which are generated at the drop of a hat, and with a lot of details as well.
Prompt Engineering: Is it an art or science? Or both?
Let’s understand Prompt engineering more.
Well, it is the practice of designing and refining prompts—questions or instructions—to elicit specific responses from AI models. More closely, it’s interface between human intent and machine output.
We are already leveraging a lot of Prompt Engineering in our day to day lives
- Text-based models (ChatGPT)
- Image generators (like Dall-E)
- Code generators (GitHub Copilot)
Useful Approaches for better output
While there are multiple ways to articulate the prompt, I came across a simple yet interesting model to fine tune the prompt from a user perspective.
It is based on the “5W+1H” approach, which talks about crafting the prompt considering all the Ws and H in mind to be able to give the LLM the right context to traverse all the tokens towards a meaningful outcome.

Image 1: The 5W+1H Approach
What Skills are needed for Prompt Engineering?
Prompt engineering is an amalgamation of both technical and non-technical skills.

Image 2: Skills of a Prompt Engineer
Relevance in Today’s tech driven world
As AI continues its footprint across all sectors, some of the areas there prompt have started making an immediate impact are the customer service bots.
Some of the popular airlines have already deployed chatbots for handling customer queries. While I happened to get my queries answered through an interaction with chatbots lately, this seem to gain more accuracy as the inputs and training of the models ‘learn’ more over the period. One important aspect is that these bots are already helping with optimizing the support cost by around 30%. However, the key is a well-crafted prompt that will help the bot to respond with the right and relevant information and reducing the cycle time in the process.
Prompt engineering is indeed crucial in an AI-powered world. Its importance will only continue to amplify.
Towards a bold new future
As AI models become complex and get leveraged by applications around us, the need for an effective communication with them becomes more and more important. Also, with the advent of tools that will simplify technology, the role of prompt engineers will gain more importance towards building, refining, and defining the right interfaces to augment human capabilities and democratize the use of AI.
As Stephen Hawking said. “Success in creating AI would be the biggest event in human history.” As AI and more specifically generative AI becomes more advanced, prompt engineering will keep playing a critically important role.
That of augmenting human productivity and creativity by establishing an increasingly more seamless connect between the man and machine.
At Infogain, we are looking forward to see how this bold new world shapes up and also help you get there.
While data offers immense potential to improve decision-making and innovation, it also presents significant challenges for organizations. Traditional centralized data platform approaches are inadequate for handling the complexities of modern enterprises, leading to issues such as data quality problems and lack of clear data ownership. Here’s where the data mesh architecture emerges as a game-changer.
Data Mesh is an architectural framework that enables decentralized data ownership, domain-oriented data as a service, federated governance, higher data quality, and easier data sharing.
Organizations can achieve a scalable data mesh architecture by leveraging a unified data platform like Microsoft Fabric, unlocking the benefits of decentralized data ownership and improved data governance.
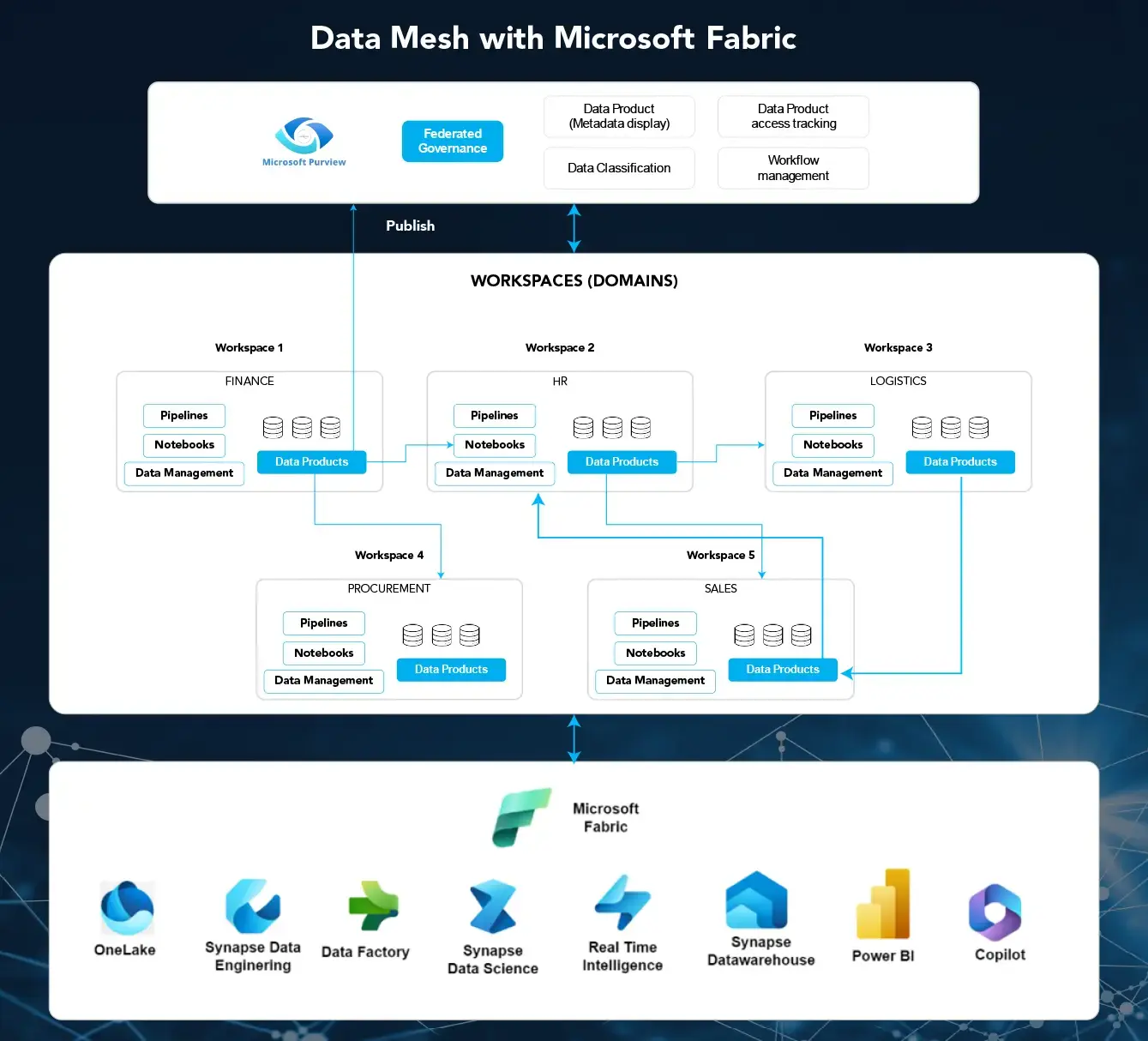
Image 1: Data Mesh with Microsoft Fabric
Microsoft Fabric supports multiple workspaces. Each workspace functions as a domain. Fabric extracts data from various sources and processes it using data engineering or machine learning services and stores it in OneLake. All data, pipelines, notebooks, etc, related to a domain can be grouped under a single workspace. Domains own their artifacts and define access controls, ensuring ownership for each specific domain. Fabric capacities (subsets of workspaces) can be created if data is scattered across different regions. This ensures regional data artifacts and helps ensure regulatory compliance.
Data products can be shared with other teams through shortcuts, ensuring shared data access without data duplication or reprocessing. Microsoft Fabric, in conjunction with Purview, provides a data product view for the entire organization. This facilitates Data as a Service (DaaS) by exposing data product metadata to other teams. Teams can view a list of data products available across different domains, request access, and easily consume and integrate the data they need. This eliminates the need to understand the underlying complexities of data storage and management. This enables workflows for requesting data product access, approval, and access management. This creates an auditable history for future reference. Additionally, Fabric with Purview maintains sensitive data classification and lineage, ensuring regulatory compliance.
As a SaaS platform, Microsoft Fabric empowers users with self-service provisioning of its various services, including OneLake data storage, data engineering tools, machine learning capabilities, real-time analytics, and visualizations. This eliminates bottlenecks associated with traditional IT models, allowing users to access and utilize the tools they need faster to gain insights from data.
Federated governance in Fabric is more flexible. Core governance policies are centrally maintained, while domain teams can define and control access and pipelines within their domain workspace based on specific needs. Each domain team is responsible for adhering to governance policies and ensuring their data products comply with the necessary compliance requirements. This federated governance model enables accountability, transparency, and compliance.
While Fabric offers an out-of-the-box data mesh implementation, iRAPID (Infogain’s accelerator toolkit) streamlines implementation by facilitating the reuse of existing metadata-driven ingestion and data quality frameworks. Additionally, iRAPID can automate the migration process from Databricks to Fabric, which is particularly useful for migration scenarios.
In conclusion, as enterprises modernize their data landscape, data ownership, regulatory compliance, increased security, and agility become critical considerations. The Data Mesh framework empowers organizations to address these challenges. Microsoft Fabric facilitates Data Mesh implementation with ease, while Infogain’s iRAPID toolkit further accelerates the process by facilitating framework reuse and migration automation.
We are all familiar with Retrieval Augmented Generation (RAG) by now. RAG is a framework designed to enhance text quality by integrating relevant information retrieved from an external knowledge base into the generated content. By combining retrieval mechanisms with generative capabilities, RAG produces more accurate, contextually appropriate, and informative text, significantly improving the overall results.
Recently, Agentic RAG has emerged as a new and powerful AI technique. In this blog, we’ll examine the problems with traditional RAG, then dive into the next advancement in the field of large language models (LLM)—agentic RAG—and explore its features and benefits.
A typical RAG pipeline involves:
- Data Indexing
- User Query
- Retrieval & Generation
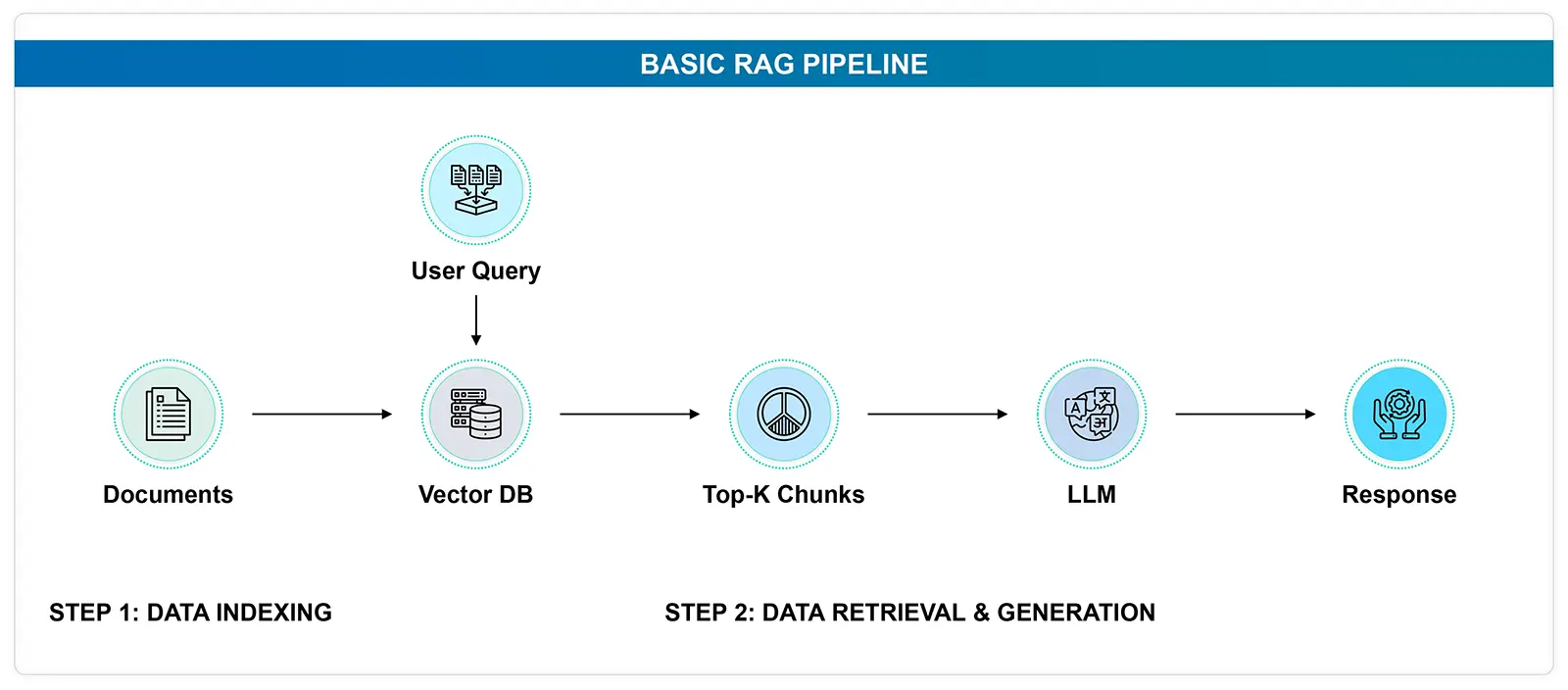
Problems with Traditional RAG:
- Summarization issues: Summarizing large documents can be tricky. The traditional RAG framework retrieves the top K chunks and may miss crucial information if the document is extensive.
- Document comparison challenges: Comparing documents effectively is still a hurdle. The RAG framework tends to pull random top K chunks from each document, often leading to an incomplete comparison.
- Structured data analysis needs: Handling structured data queries, such as determining an employee’s next leave based on their region, proves to be a challenge. Accurate retrieval and analysis of specific data points aren’t spot-on.
- Dealing with multi-part questions: Tackling multi-part questions remains a limitation. For instance, identifying common leave patterns across all regions in a large organization is difficult when constrained to K chunks, which limits comprehensive analysis.
Now, to overcome these limitations, Agentic RAG comes to the rescue. Agentic RAG = Agent-based RAG implementation
Beyond Traditional RAG: Adding Agentic Layers
Agentic RAG revolutionizes the way questions are answered by introducing an agent-based framework. Unlike traditional methods that rely solely on large language models (LLMs), Agentic RAG employs intelligent agents to tackle complex questions that require:
- Intricate planning
- Multi-step reasoning
- Utilization of external tools
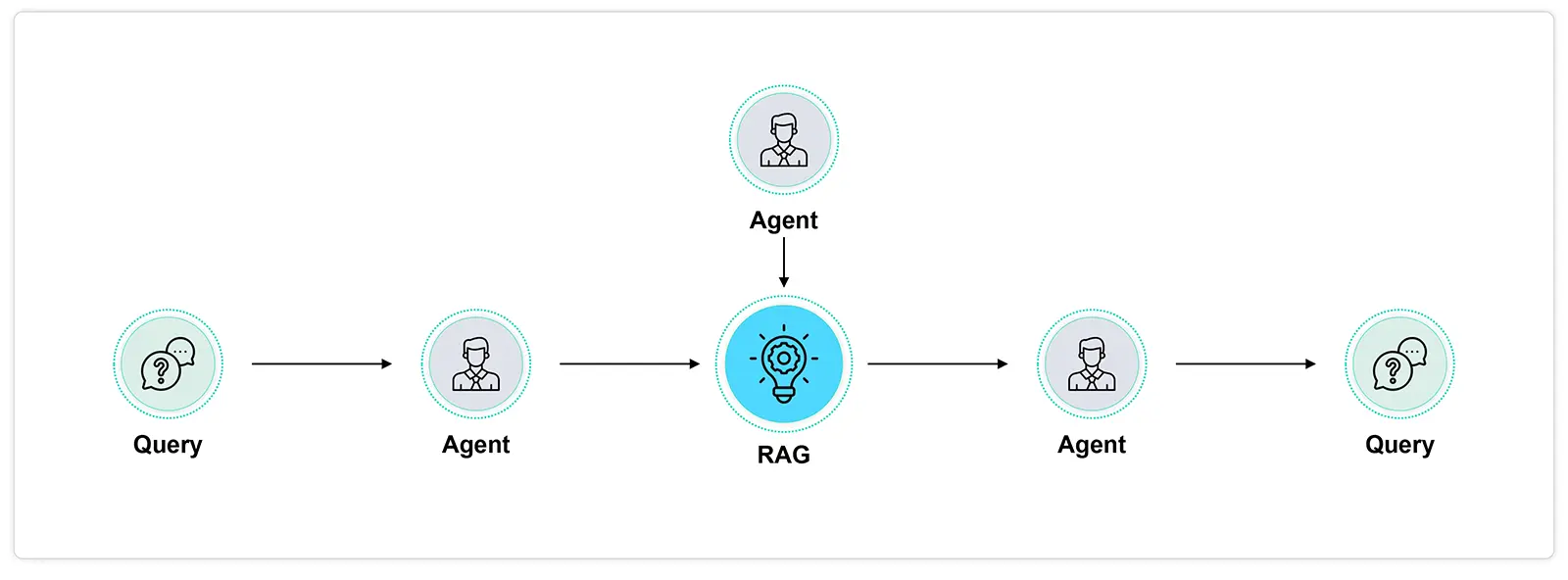
These agents act like expert researchers, adeptly navigating multiple documents, comparing information, generating summaries, and delivering comprehensive and accurate answers. It’s like having a team of specialists working collaboratively to meet your information needs. Whether you need to compare perspectives across documents or synthesize information from various sources, Agentic RAG agents are equipped to handle the task with precision and efficiency.
Why Agentic RAG?
An AI agent is essential for:
- Reasoning: Determining which actions to take and their sequence.
- Task Management: Using agents instead of LLMs directly for tasks requiring planning, multi-step reasoning, tool usage, and learning over time.
In the context of RAG:
- Agents enhance reasoning before selecting RAG pipelines.
- Improve retrieval or re-ranking processes within a pipeline.
- Optimize synthesis before responding.
This approach automates complex workflows and decision-making for non-trivial RAG use cases.
Agentic RAG Benefits:
- Orchestrated question answering: Breaks down the process into manageable steps, assigns appropriate agents, and ensures seamless coordination for optimal results.
- Goal-driven: Agents understand and pursue specific goals, allowing for more complex and meaningful interactions.
- Planning and reasoning: Agents can determine the best strategies for information retrieval, analysis, and synthesis to answer complex questions effectively.
- Tool use and adaptability: Agents leverage external tools and resources, such as search engines, databases, and specialized APIs, to enhance their information-gathering and processing capabilities.
- Context-aware: Systems consider the current situation, past interactions, and user preferences to make informed decisions and take appropriate actions.
- Learning over time: Agents are designed to learn and improve, expanding their knowledge base and enhancing their ability to tackle complex questions.
- Flexibility and customization: The framework provides exceptional flexibility, allowing customization to suit specific requirements and domains.
- Improved accuracy and efficiency: By leveraging the strengths of LLMs and agent-based systems, agentic RAG achieves superior accuracy and efficiency in question answering.
RAG Agents can be categorized based on their functions, including routing, one-shot query planning, tool use, Reason + Act (ReAct), and dynamic planning & execution. These functions vary in complexity, cost, and latency and range from simple, low-cost, low-latency tasks to complex, high-cost, high-latency operations.
For example:
- Routing Agents (aka Routers): The routing agent relies on an LLM to select the appropriate downstream RAG pipeline. This process is known as agentic reasoning, since the LLM analyzes the input query to determine the best-fit RAG pipeline. It represents the most straightforward form of this type of reasoning.
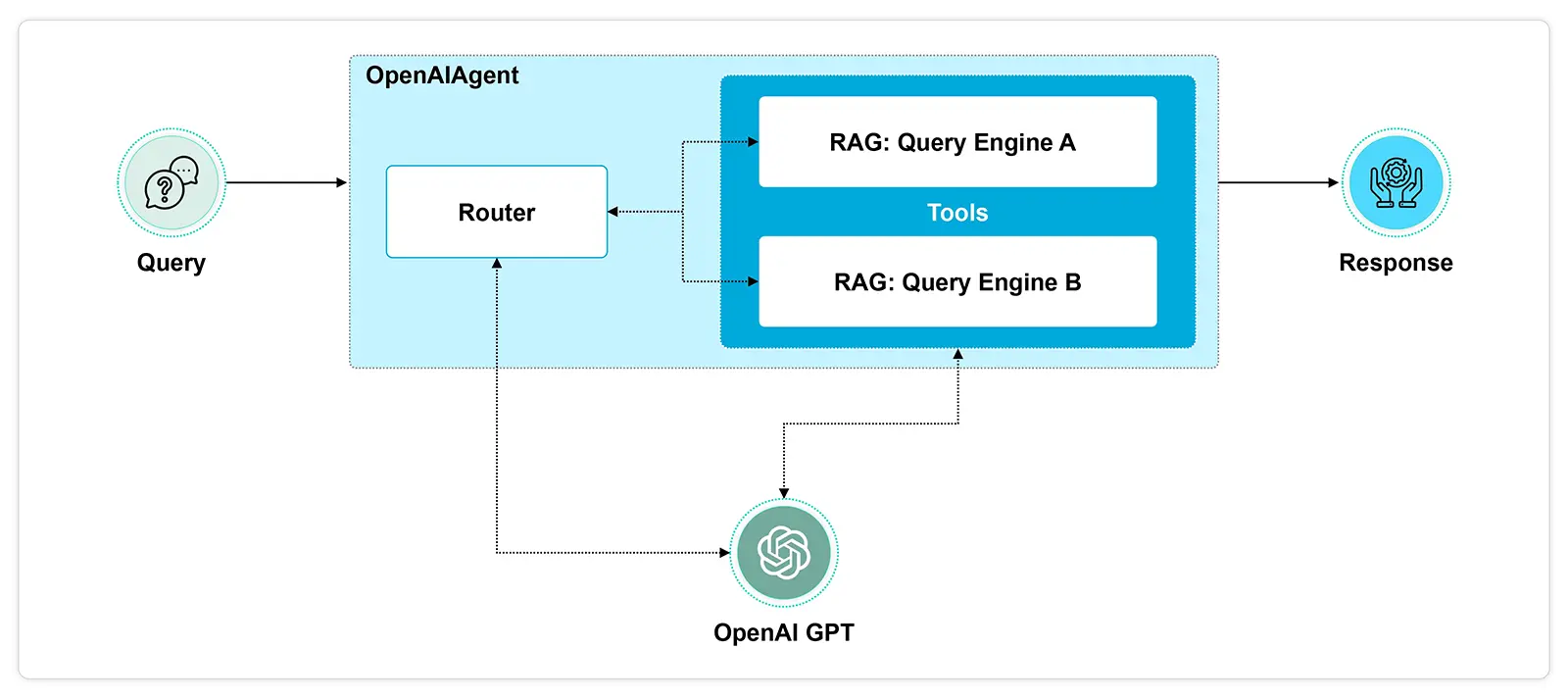
One scenario may involve choosing between summarization and question-answering RAG pipelines. The agent evaluates the input query to decide whether to route it to the summary query engine or the vector query engine.
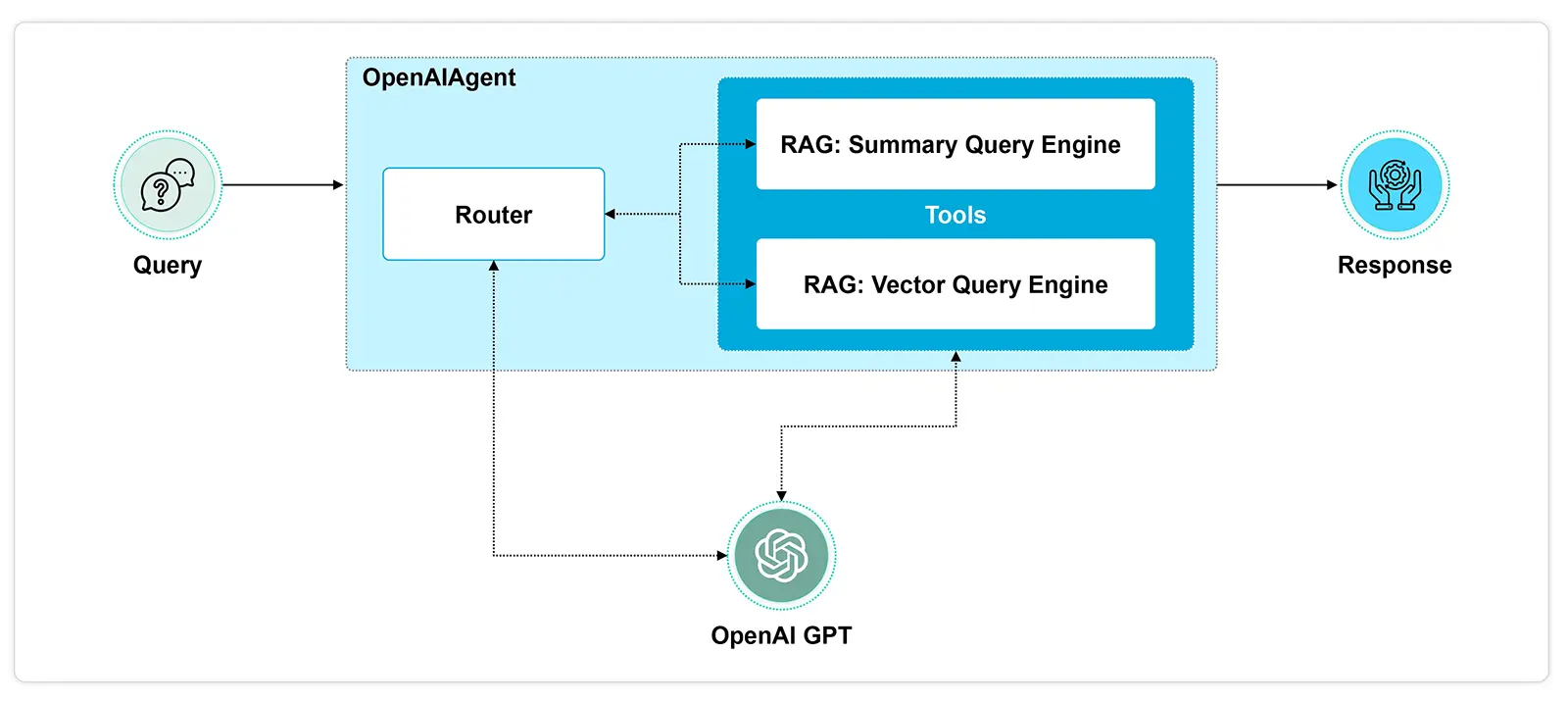
- Query Planning Agent: It simplifies a complex query by dividing it into smaller, parallelizable sub-queries. Each sub-query can be executed across various RAG pipelines that are linked to different data sources. The individual responses from these pipelines are combined to form the final response.
In essence, the process involves breaking down the query into manageable parts, executing them across suitable RAG pipelines, and finally merging the results into a coherent response.
Several other flows are there based on the functionalities and use cases.
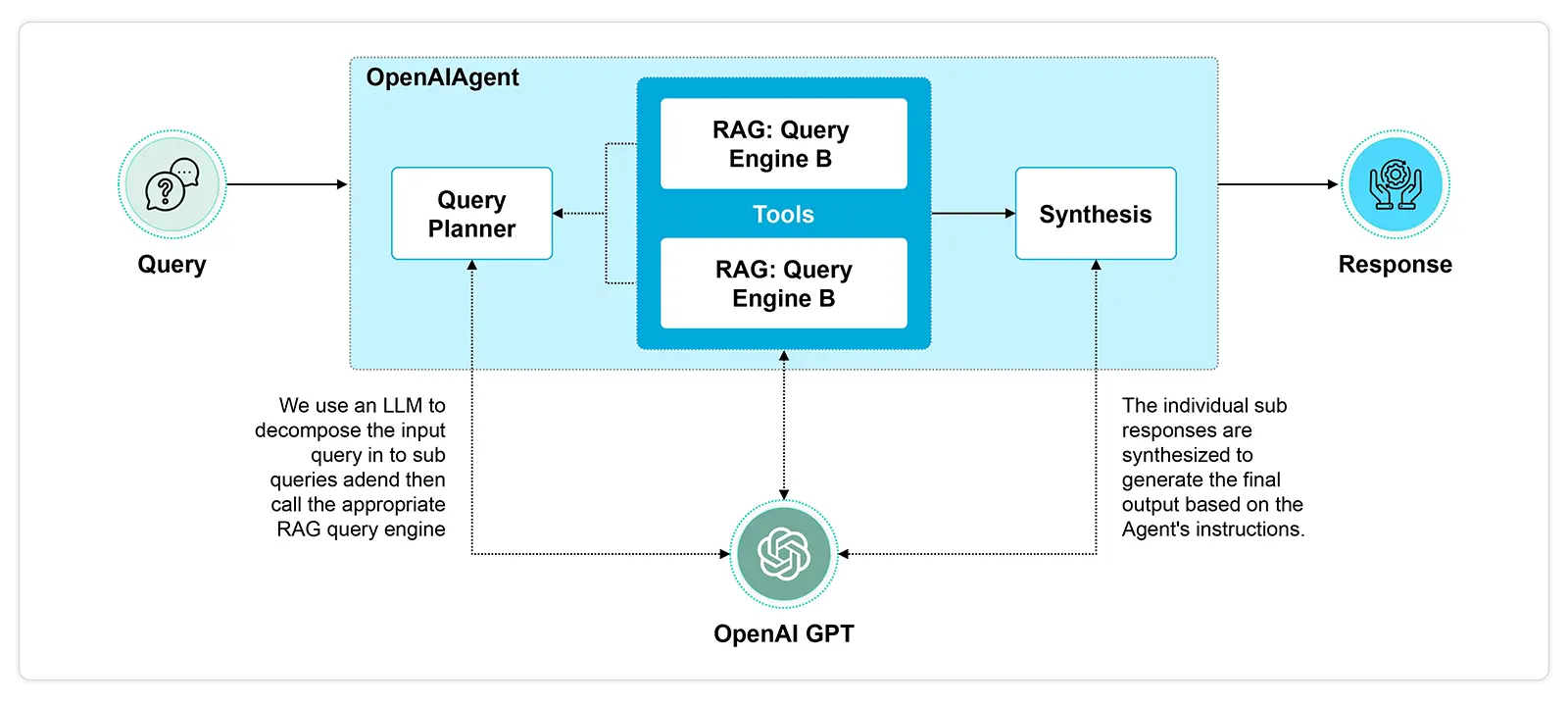
Agentic RAG represents a significant advancement in the field of large language models. By incorporating custom agents that can interact with multiple systems, automate reasoning, and dynamically select the best tools for the task at hand, Agentic RAG addresses the shortcomings of traditional RAG. This makes it a more effective solution for handling complex queries and a wider range of use cases.
For more information, visit our website and check out Infogain’s analytics, data, and AI services.
Today’s digital-first customer is pushing the retail industry to a bold new world where creating the perfect product is only the first piece of the puzzle. Modern retailers are looking to build deeper customer loyalty expectations, deepen customer loyalty, and increase sales by creating meaningful customer experiences.
This handpicked collection showcases how our customers have leveraged our capabilities in AI, data, analytics, forecasting, and other digital solutions to:
- Increase RoI
- Improve brand loyalty
- Strengthen brand recognition
- Increase forecasting quality
- Unlock valuable customer insights
And more.
Get your copy today to know more.
It was great to see everyone (all 30,000 of you) at Google Next last week. Four things stand out as potential game-changers:
- Gemini Pro 1.5: I loved hearing about this release and how it powers so many new capabilities, especially for code acceleration (Code Assist) and operations (Cloud Assist). They’ve got an integrated vision that really differentiates them in the market.
- RAG + Agents: As retrieval-augmented generation (RAG) goes mainstream, the next generation of GenAI powered capability will be powered by agents. As I’ve written before, combining RAG and conversational search enables some interesting new use cases and tools like Google’s new Vertex AI Agent Builder will make agent development even easier.
- GenAI is delivering value: Everyone at Google Next was talking about how our entire industry is moving past proof of concept for GenAI-enabled solutions and into production. Takeaway? The solutions being deployed are delivering real business value for enterprise clients across industries.
Finally, Google owns their entire AI platform – from chips to agents, end to end – so they’ll be able to bring innovative, integrated solutions to market faster than they ever could before. They can engineer an entire solution top to bottom and say, “Yep, it’s all ours.”
As companies continue to accelerate their digital transformation journeys, every industry has begun to implement AI-enabled solutions, and new use cases come to light every day. But no matter how far a company has come in its journey, one fact remains inescapable: the cloud is the only way to unlock the full value of data. WHY? AI powered transformation has a dependency on a number enabling capabilities provided by the cloud: large storage, ubiquitous access and scaled compute capacity.
At Infogain, we’ve supported hundreds of customers in their cloud journeys. We’ve learned that cloud readiness and adoption determines how quickly transformation moves forward, and while a cloud-native approach enables greater efficiency and savings, a lot of people still focus on the wrong things.
Not all workloads are created equal.
Many customers have made a shift – containerizing workloads and pushing them to the cloud. This approach has benefits but returns diminish at some point. It’s critical to consider which applications should be rewritten to leverage the cloud provider’s native services to improve performance and save money, and which can continue to operate as they are.
Suppose you have a back-office COTS application for expense reconciliation. It will neither evolve nor scale, and the app vendor maintains it. Here the best path is to move it to the cloud in a VM environment that matches its current deployment footprint.
For an extremely complex customer-facing application with a large code base that suffers frequent outages, it’s better to avoid disrupting the customer experience and re-platform the application with no or minimal code changes. Instead, containerize the application, move the databases to managed database instances, and/or deploy the application in a managed app hosting service.
When a customer wants to significantly upgrade their offerings / services that will disrupt the business domain, it becomes a mission critical program with the potential for 10X / 100X future growth. The related applications simply must scale. In this case, rearchitect the application to create a truly cloud-native instance with planet scale capabilities.
Portability and being cloud-agnostic may not matter.
The fastest path to going cloud-native is to leverage the hyperscaler platforms. These providers are not going away, and their security and privacy controls define the state of the art. Your biggest investments will be in training and keeping people, so it might make more sense to shift the right workloads to one platform, master it, and sidestep the complexity and cost of building teams to leverage multiple platforms.
That said, portability and being cloud agnostic can become essential at specific times. Hyperscalers constantly experiment and release native services to speed up application development and deployment. These services can require very specific coding and configuration, but some of them die due to lack of adoption. Others evolve to follow the hyperscaler’s roadmap, which can create major overhead for the development team. In this case, code on an open source or community-driven framework and deploy in cloud in the managed instances for these frameworks.

Automate manual work.
It shouldn’t take people to create, test, and iterate marketing campaigns, update products and pricing, and pull reports from data. Automating these tasks gives your people time for things that move the business forward like turning insights into campaign ideas that engage users. Other potential cloud workloads include using GenAI for deployments, monitoring, and support.
Automations fall into four categories:
- Build and release automation: This CI/CD buildout automates every step from when code is checked in to the time it lands in production.
- Infrastructure as Code (IaaC): Code the cloud platform that you want to deploy and run it through automation as in build and release automation.
- Cloud Instrumentation automation: Irrespective of applications being deployed, you need guardrails for basic platform monitoring, backup policies, and access policies. These guardrails typically are scripted and deployed so the cloud environment enforces them when new resources are created.
- Ops automation: You can script patching of compute resources, DR testing, backup testing, and other operation activities in the cloud platform. Ideally these are scripted to eliminate manual effort.
Having access to on-demand storage and compute at scale lets companies unlock the value their data contains in new ways. As use cases evolve, we believe that even more workloads will move to cloud-native apps. As your transformation journey unfolds, you can begin to create the foundation you’ll need with your existing people and budgets by considering the five areas we’ve outlined above.
For digital-native customers, the experience of a product goes well beyond a smooth purchasing experience. Rising customer expectations are driving a massive shift in the retail industry, forcing category managers, space planners, sales executives, marketing leaders, and analytics professionals to think differently. Increasingly, innovative leaders are looking to leverage generative AI, cloud, and other digital technologies to transform their businesses and thrive in this bold new world.
This was evident in the recently concluded CMA Conference in Dallas, an event where I had the opportunity to interact closely with sales, marketing, and analytics leaders from retail and CPG companies. The conversations made it clear that the retail landscape is going through a seismic shift. Here are the key takeaways from the event:
- The new-age retail customer is looking for a seamless, omnichannel, hyper-personalized experience that makes their life easy and gives the right option at the right time on the right device.
- To address this, category managers are acquiring intelligent insights that can help them understand customer behaviors and preferences, develop competitive pricing, and more.
- Retailers are leveraging the potential of generative and predictive AI across a broad spectrum of functions.
AI and retail’s bold new future.

- Companies are realizing they can bring in their own sensitive, proprietary data to build a knowledge base and then unleash the power of AI safely and securely by using retrieval augmented generation (RAG).
- Retailers see the potential of generative AI to extract market and competitive insights from a knowledge base of relevant material. However, they are also keen to combine generative and predictive AI to unlock more significant business impacts. For instance, imagine a system that doesn’t just summarize how a competitor performed last quarter but predicts how they will perform next quarter.
- Predictive AI is still very relevant. Category managers are leveraging the power of predictive AI models to make data-driven decisions for better inventory management and product selection.
- Retailers are exploring recommendation engines that can provide hyper-personalized purchasing experiences.
- Many anticipate that more high-profile generative AI security and privacy gaffes might occur, which may influence consumer attitudes. The consensus is that robust regulatory oversights will address this in the future.
- As the retail market evolves at an unforeseen pace, companies are looking to partner with agile service and solution providers who are actively researching the latest developments and have the proper skill set to take projects off the ground quickly and swiftly.
- The retail industry is also monitoring big-ticket developments in generative and predictive AI. For instance, there is high anticipation of how Apple’s launch of Vision Pro can pave the way for renewed interest in AR / VR shopping experiences and the launch of Open AI’s next powerful model this year.
In Conclusion
The mix of new-age buyers and new-generation technology is pushing the boundaries of the retail industry to a bold new world full of previously unforeseen possibilities. Leveraging Infogain’s years of industry experience and deep domain expertise, we have been helping retail organizations make this leap.
Let us embark on this bold new journey. Together.