Empowering an AI Transformation at Microsoft Ignite
We joined over 14,000 attendees at this year’s Ignite in in Chicago, November 18-22. The theme focused on how Microsoft is empowering their customers and partners through AI transformation. Microsoft Ignite is an amazing event, giving IT professionals the opportunity to ramp up their skillsets with an array of more than 800 sessions, demos and expert-led labs from Microsoft and their partners.
This year, there was buzz and an excitement particularly around Copilot and Security. The event also showcased cutting-edge advancements in AI, cloud computing, hybrid work solutions and accessibility. Generative AI has taken on an expanded role in Microsoft, with tools like CoPilot transforming productivity across M365 and Azure.
The real-time speech and video translation innovations within MS Teams were impressive. Individuals can now communicate across Teams calls in their preferred language and receive a translation to the recipient’s language in real-time. This demo was fascinating to see live!
The latest trends included an emphasis in hybrid collaboration technologies, seamless connectivity, and integrated solutions, all with security underpinning everything. For example, new products like Microsoft Security Exposure Management provides more proactive security monitoring by unifying disparate data silos for visibility of end-to-end attack surface and automates the generation of possible attack paths.
At the event, we observed key product launches across AI, cloud computing, and hybrid workspaces, including:
- Copilot Plus PCs is a new class of Windows PCs optimized for AI-driven workloads and hybrid work environments. These devices are designed for seamless integration with the cloud and Microsoft’s distributed computing infrastructure, enhancing productivity for remote and on-site teams.
- Microsoft Link is a terminal device that connects to a Windows desktop in the Microsoft Cloud. It is tailored for shared workspaces, focusing on AI-enhanced collaboration and hybrid work.
- Teams Agents are AI-driven agents for Microsoft Teams, such as Facilitator Agent that provides real-time meeting notes and insights and Interpreter Agent that offers live translations during meetings, launching early next year.
- Updates to security (Microsoft Purview) has new features targeting data governance and security, specifically addressing AI misuse, including malicious intent detection and prevention of risky AI-generated prompts.
- Microsoft 365 enhancements in Microsoft 365 Copilot have new features like action cards for task delegation, document creation, and summarization within organizational workflows.
- Azure OpenAI Integrations offer expanding tools for developers to build scalable AI applications, leveraging OpenAI’s models directly within Azure.
- Security-Focused Tools are new tools and updates in Microsoft’s Secure Future Initiative (SFI) designed to strengthen cybersecurity measures across platforms.
Ignite 2024 reinforced Microsoft’s vision of driving innovation through AI-driven tools. In addition, it was a fantastic opportunity to network with Microsoft’s stakeholders and partners. If you want more details, you can also watch most of the keynotes and sessions on demand or read the latest in the Microsoft ignite Book of News.
We’re a Microsoft Gold Partner, and every day, we enable our customers to deploy Microsoft technologies and build long term value. Contact us with your questions.
Every ML project begins with an initial model development phase that includes exploratory data analysis, feature engineering, model creation, training, and evaluation. During this phase, data science teams prioritize delivering a high-performing model, however, generating the ML models goes beyond this phase. While model development requires deep data science expertise, deploying the model demands operational skills.
The key challenges in moving ML model from development to production includes:
- Data issues
- Code issues
- Tracking of models
- Deployment issues, and
- Scalability issues
We propose a six-step method for ML Operationalization that can help overcome these challenges.
Download the whitepaper to read more.
Will a large context window eliminate the need for a RAG approach?
Although the future of GenAI is still very much a blank canvas, senior leaders still need to ensure that they make wise choices regarding how it will and will not be used within their companies. These leaders, especially the ones in roles focused on growth, commerce, innovation and operations, need to fully understand the nuances of the various AI technologies being proposed within their orgs, as well as the long-term benefits and issues that these technologies can bring to the table.
Take retrieval-augmented generation (RAG) for example. Companies have begun to use this rapidly evolving technology to leverage vast amounts of unstructured data, but already there is talk of “RAG killers” that can outperform it.
In natural language processing (NLP), the “context window” is the span of text that an algorithm or model considers while understanding or generating language. New supermassive context windows can accommodate over one million tokens, which drives the idea that they could replace RAG. These context windows expand the range of use cases, but that doesn’t make them RAG killers, nor do executives need to choose between one or the other as they chart the futures of their companies.
Context windows include a certain number of words or tokens surrounding a target word to capture relationships and meaning within the text. For example, in models like Word2Vec, the context window helps in understanding semantic relationships by analysing words before and after a target word. In transformers like GPT-3, the context window is the portion of text the model uses to generate or predict the next token, directly impacting the coherence and relevance of its output.
Figure 1. Context Window
RAG is a hybrid model that combines the strengths of retrieval-based and generation-based approaches. In essence, it retrieves relevant information from a large corpus or database (like a search engine) and then uses that information to generate a coherent and contextually appropriate response or piece of text. This allows for more accurate and informed responses, particularly in scenarios where the model might not have all the required information within its training data alone.
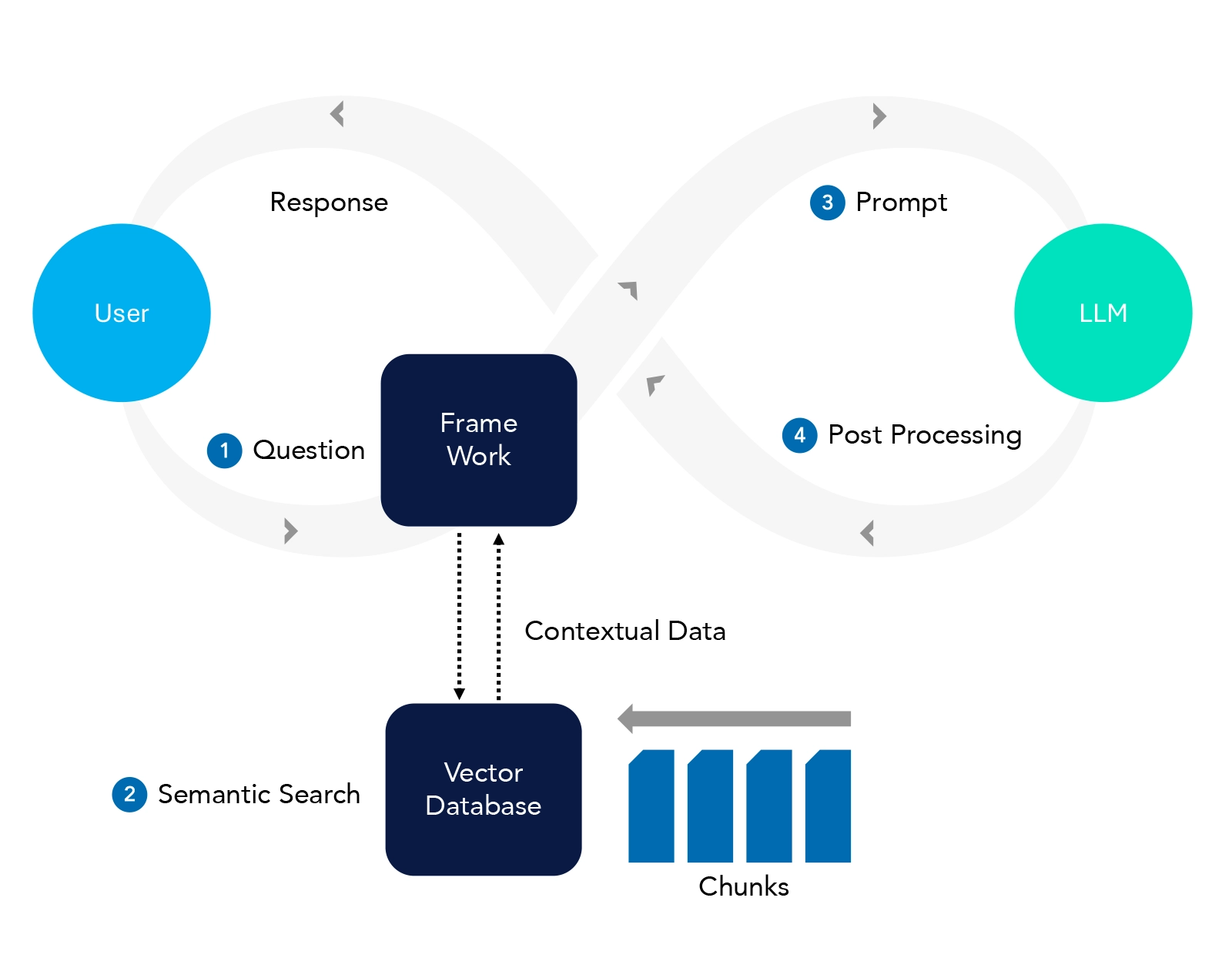
Figure 2. RAG Architecture
What are the key differences?
As with any technology, the ideal choice for a specific enterprise depends on the structure of that enterprise, its legacy stack, ability to support new technologies, and dozens of other variables.
Here are some of the key differences between RAG and long context windows.
| Feature | Long Context Window | RAG Model |
| Capacity | Can handle up to thousands of tokens | Efficient data handling by retrieving smaller text chunks |
| Perplexity | Lower perplexity due to broader context awareness, reducing ambiguity | Efficiently reduces perplexity by narrowing down to relevant information |
| Coherence | High coherence across contents, preserving narrative flow | May struggle with coherence across diverse retrieved sources |
| Dependence | Dependence on input context | Dependent on external databases or knowledge sources |
| Diversity | Limited by the scope of pre-trained data | Better handling of diverse information from multiple sources |
| Precision | General high-level precision, not detail-oriented | High precision in answering specific queries accurately |
| Consistency | Strong narrative consistency across long texts | Inconsistent context due to varied retrieved sources |
| Context Relevance | Maintains relevant context throughout the document | May vary, depending on the quality of retrieved documents |
| Current Information | Limited to knowledge up to the training cut-off | Better at incorporating the most recent data |
| Memory Intensive | Requires significant GPU memory for large context processing | Distributed load between retrieval and generation processes |
| Latency | Higher latency due to handling extensive textual data | Faster inference balanced by retrieval workload |
| Optimization | Requires advanced hardware optimization for effective use | Lower hardware requirements compared to LCW |
| Adaptation | Limited adaptability due to fixed pre-trained data | Highly adaptable, quickly integrates new data |
| Customization | Less customizable without extensive re-training on new data | Easily customized for domain-specific needs via retrieval tuning |
| Environment Compatibility | Challenging integration in diverse environments without extensive tuning | Supports frequent updates with minimal re-training |
| Ideal For | Document summarization, in-depth analysis, thesis writing | Real-time Q&A, chatbots, and dynamic content retrieval |
| Less Suited For | Real-time information retrieval, dynamic environments | Long-form content generation without retrieval refresh |
| Content Generation | Ideal for generating comprehensive, unbroken narratives | Limited by the need for real-time retrieval |
| Training Time | Longer training times due to heavy data processing requirements | Faster training if pre-established retrieval corpus is available |
| Inference Time | Slower inference with large contexts, impacting responsiveness | Faster inference balanced by retrieval workload |
| Algorithmic Complexity | High complexity making it difficult to optimize | Relatively simpler algorithms with modular retrieval and generation components |
| Integration | Complex integration due to hardware and optimization needs | Easier integration with existing systems due to modularity |
| Maintenance | High maintenance with frequent updates required | Lower maintenance mainly focusing on retrieval database updates |
| Deployment | Challenging deployment in resource-constrained environments | Simpler deployment with standard hardware support |
| Cost | High, requires extensive training and updating | Minimal, no training required |
| Data Timeliness | Data can quickly become outdated | Data retrieved on demand, ensuring currency |
| Transparency | Low, unclear how data influences outcomes | High, shows retrieved documents |
| Scalability | Limited, scaling up involves significant resources | High, easily integrates with various data sources |
| Performance | Performance can degrade with larger context sizes | Selective data retrieval enhances performance |
| Adaptability | Requires retraining for significant adaptations | Can be tailored to specific tasks without retraining |
It’s always a balance.
Both large context window and RAG systems have their own pros and cons, but large context LLMs are not always RAG killers.
The Long Context Window model excels in maintaining extensive context and coherence, suitable for comprehensive document processing but demands higher computational resources.
- Document Summarization and Analysis – A long context window model can read and summarize entire documents, research papers, legal contracts, or technical manuals while maintaining overall context and coherence throughout.
- Thesis Writing and Long-Form Content Generation – Long context window models are ideal for generating cohesive long-form content, such as research papers, white papers, or blog posts, where maintaining the flow and narrative consistency across multiple sections is critical.
- Legal Document Review and Compliance – When reviewing lengthy legal documents or contracts, these models can ensure that no details are lost by understanding context across tens of thousands of words.
In contrast, the RAG model is optimal for real-time information retrieval, offering flexibility and precision with lower resource use, making it ideal for dynamic querying applications like chatbots and Q&A systems.
- Real-Time Q&A Systems and Chatbots – RAG models are highly effective for building chatbots that retrieve up-to-date information from external databases and provide precise, real-time answers based on current or domain-specific data.
- Dynamic Product Recommendations – In e-commerce or financial services, RAG models can provide personalized product recommendations by retrieving data about customer behavior and preferences from multiple sources.
- Customer Support – RAG models can enhance customer service by pulling from various knowledge bases, product documents, and FAQs, to provide accurate and relevant responses without the need for extensive retraining.
A hybrid approach (Long Context Window LLM + RAG) is the need of the hour, and can make applications more robust and efficient.
- Enhanced Flexibility – The hybrid approach combines the extensive context awareness of long window models with the dynamic retrieval capability of RAG models, enabling applications to seamlessly handle both structured and unstructured information at scale.
- Improved Precision and Contextual Understanding – By retrieving the most relevant information in real-time through RAG while maintaining overall coherence through a long context window, the hybrid model enhances accuracy in responses, particularly for complex, multi-faceted queries.
- Resource Efficiency – The hybrid model can offload some of the computationally intensive processes (like full document parsing) to RAG systems, making it possible to scale large AI models while optimizing hardware and resource usage.
As enterprise leaders consider the future of AI within their companies and organizations, both RAG and large context windows offer significant benefits. Wise leaders will understand the ramifications of each technology, then choose how to combine and balance them based on their vision for the future of their enterprise.
What happens when customers have too many choices?
As people ponder what to buy, many brands offer recommendations. The recommender systems that enable this leverage data on what users have already liked or bought and are particularly useful when brands offer such a huge array of products that the choices can overwhelm the customer, whether that’s music, movies, accessories, or other products.
Recommender systems are integral to modern digital ecosystems. Well-executed recommendations can increase the customer’s affinity for a brand and can drive revenue for brands by increasing cross-sell and upsell. But when recommender systems don’t deliver truly personalized experiences, customers become disillusioned with the underlying brand, with disappointing results for the bottom line.
Traditional Recommender System Techniques
Core recommendation engine functions like handling user interactions and maintaining scalability still rely on traditional techniques, which can include:
- Collaborative Filtering relies on user-item interactions, making recommendations based on the preferences of similar users or items. It’s like asking a friend with similar tastes what movies you should watch next.
- Retailers often use Association Rules (Market Basket Analysis) to identify items that frequently co-occur in transactions—the customer who buys bread might also buy butter.
- Variable-order Markov Chain Analysis predicts user actions based on their sequential behavior history. It’s akin to predicting the next word in a sentence based on the previous words.
- Matrix Factorization is a cornerstone of many collaborative filtering systems. It decomposes a large user-item interaction matrix into lower-dimensional matrices to uncover latent factors that explain observed preferences.
GenAI can’t replace recommenders.
But it can help brands fill data gaps and understand nuanced user behavior by generating synthetic data, creating personalized content, and providing context-aware insights that enhance the results that recommenders provide.
Overcoming Data Scarcity and Cold Start Problems
These traditional methods rely heavily on historical user-item interaction data. But when that data is limited or missing, they can struggle, especially with the “cold start” problem –– making recommendations to new users or introducing new items to existing users.
To address this, brands can use GenAI to create synthetic data that mimics real user interactions, then use it to enrich existing datasets, leading to more robust and nuanced recommendations. It most often does this with two techniques:
- In Generative Adversarial Networks (GAN), two neural networks compete, creating new data (like forging a painting) and judging its authenticity. Over time, the forger gets better at creating realistic data. In recommender systems, GANs can create fake user interactions for new users or unpopular items, improving recommendation accuracy.
- Variational Autoencoder (VAE) models learn to compress data into a simpler form and recreate it. They can then use this “code” to generate new data points similar to the originals. In recommender systems, VAEs can create synthetic user profiles or interactions, enriching data and leading to better recommendations.
Hybrid models can leverage both traditional methods and GenAI. For instance, they might use collaborative filtering to identify similar users and recommend items based on their preferences while simultaneously using a VAE to generate synthetic interactions for users with sparse data, enhancing the performance of the collaborative filtering model.
Unified Propensity Models
Recommender systems traditionally use propensity models to drive upsell and cross-sell, predict churn, and perform other functions. These models are accurate but can be complex and resource intensive. GenAI offers an alternative, a “decent proxy” for these models that can analyze trends and user behavior. Although not necessarily as precise, GenAI can achieve good results with significantly less effort, so long as we remember that GenAI models themselves can inherit biases from the data used to train them.
While GenAI can be more efficient , individual propensity models might still provide slightly more accurate results in some scenarios. The key lies in finding the right balance—so when the brand has a high-value customer making a key business purchase and wants to target them with a premium product offering, it might be better to use a dedicated upsell model. For broader recommendations where speed and efficiency are paramount, GenAI’s unified approach can be highly beneficial.
Do you need a recommender system at all?
The null model—simply recommending popular items—can work surprisingly well. It’s easy to implement, requires minimal data, and guarantees users will see well-regarded products. It can be particularly useful for new businesses or those with limited data on user preferences. Focusing on popular items can also create a sense of social proof, encouraging users to choose products others have enjoyed.
But again, GenAI can play a role. It can be crucial in determining when to choose a null model over a recommender system (assuming the brand already has one). It can also analyze user behavior, interaction patterns, data availability, and other factors to predict the most effective approach for each scenario. We’re not at the point where GenAI can (or should) dictate when to switch between null models and complex recommender systems, but soon it will be able to leverage intelligent routing or agentic frameworks to make this recommendation.
Ever onward
As GenAI matures, recommender systems will transform into even more intricate tools, weaving themselves seamlessly into the fabric of digital experiences. Recommendations will not only anticipate our desires but surprise us with hidden gems. GenAI can unlock this potential, but further exploration and development are needed to bring this vision to life.
Citations
- “Why personalization isn’t enough: How to deliver customer experiences that win” McKinsey & Company Report (2022)
- “How to Avoid the Personalization Paradox: Balancing Privacy and Relevance,” https://www.forrester.com/blogs/category/personalization/ Forrester Research Report (2021)
- “Generative Adversarial Nets.” Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014), Advances in Neural Information Processing Systems (pp. 2672-2680).
- “Auto-Encoding Variational Bayes.” 4. Kingma, D. P., & Welling, M. (2014). Proceedings of the 2nd International Conference on Learning Representations (ICLR).
Every day, more enterprises leverage GenAI to enable self-service, streamline call-center operations, and otherwise improve the experiences they offer customers and employees. But questions arise about how to optimize the relationships between retrieval-augmented generation (RAG), knowledge graphs (KG), and large language models (LLM). Combining these three components in the smartest ways enables enterprise tools to generate more accurate and useful responses that can improve the experience for all users.
- A knowledge graph is a collection of nodes and edges that represent entities or concepts, and their relationships, such as facts, properties, or categories. It is used to query or infer factual information about different entities or concepts, based on their node and edge attributes.
- Retrieval augmented generation combines retrieval of relevant documents with generative models to produce more informed and accurate responses. RAG uses retrieval mechanisms to find pertinent information from a large corpus, which is then fed into the generative model to enhance its output.
- A large language model generates human-like text based on the input it receives. LLMs are trained on vast amounts of data to understand and generate natural language and can perform a wide range of language-related tasks.
Augmenting RAG with KGs leverages the structured nature of KGs to enhance traditional vector search retrieval methods, which improves the depth and contextuality of the information it retrieves. KGs organize data as nodes and relationships representing entities and their connections, which can be queried to infer factual information. Combining KGs with RAG enables LLMs to generate more accurate and contextually enriched responses.
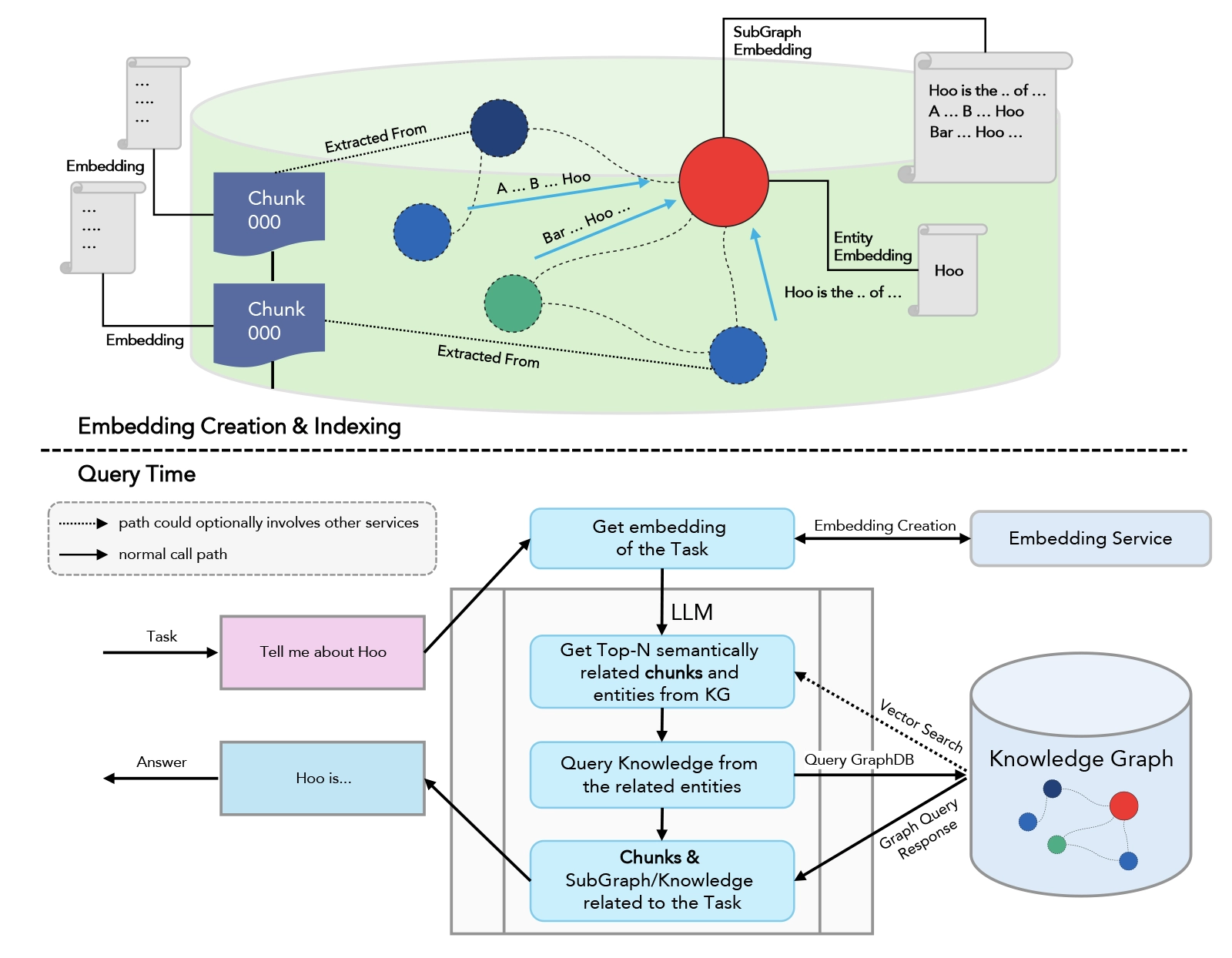
Implementing a KG-RAG approach involves several steps.
Knowledge Graph Curation
- Data Collection: Start with the ingestion of unstructured data from desired knowledge base.
- Entity Extraction: Identify and extract entities (people, places, events) from the data.
- Relationship Identification: Determine the relationships between entities to form the edges of the graph.
- Graph Building: Construct the knowledge graph using the identified entities and relationships.
- Store Embeddings in Graph Database: Generate embeddings from the knowledge graph and store these embeddings in a graph database for efficient retrieval
RAG Integration
- Document Retrieval: Use the Knowledge graph vector db to retrieve relevant documents or information chunks that the LLM can use. Similar chunks corresponding to questions are retrieved using similarity algorithms like cosine or Euclidean distance. These chunks are fed into the LLM along with the query.
- Contextual Generation: The LLM uses the retrieved information to generate responses that are contextually accurate and enriched with domain-specific knowledge.
System Optimization
- Fine-Tuning: Adjust the LLM using domain-specific data to improve response accuracy.
- Graph Updates: Continuously update the KG with new data to keep the information current and relevant.
- Efficient Prompt Engineering: Develop and optimize prompts to guide the LLM effectively, ensuring the model generates relevant and precise responses based on the retrieved information and the user’s query.
Flow diagram
When should you choose KG over RAG?
When you typically have complex queries. KGs support more diverse and complex queries than vector databases, handling logical operators and intricate relationships. This capability helps LLMs generate more diverse and interesting text. Examples of complex queries where KG outperforms RAG include
- One Page vs. Multiple Pages of the Same Document vs. Multiple Documents: KGs work well in scenarios where information is spread across multiple chunks (pages). They can efficiently handle queries requiring information from different sections of a single document or multiple documents by connecting related entities
- Multi-hop Questions: KGs support multi-hop question-answering tasks, where a single question is broken down into multiple sub-questions. For example, answering “Did any former OpenAI employees start their own company?” involves first identifying former employees and then determining if any of them founded a company. KGs enable the retrieval of interconnected information, facilitating accurate and complete answers.
When you need to enhance reasoning and inference. KGs enable reasoning and inference, providing indirect information through entity relationships. This enhances the logical and consistent nature of the text generated by the LLM.
When you need to reduce hallucinations. KGs provide more precise and specific information than vector databases, which reduces hallucinations in LLMs. Vector databases indicate the similarity or relatedness between two entities or concepts, whereas KGs enable a better understanding of the relationship between them. For instance, a KG can tell you that “Eiffel Tower” is a landmark in “Paris”, while a vector database can only indicate how similar the two concepts are.
The KG approach effectively retrieves and synthesizes information dispersed across multiple PDFs. For example, it can handle cases where an objective answer (e.g., yes/no) is in one document and the reasoning is in another PDF. This reduces wrong answers (False Positive) which is common in Vector db
Vector databases give similar matches just on text similarity which increases False Negative cases and hallucinations. Knowledge graphs capture contextual and causality relationships, so they don’t produce answers that seem similar based purely on text similarity.
| Metric | RAG | KG |
|---|---|---|
| Correct Response | 153 | 167 |
| Incorrect Response | 46 | 31 |
| Partially Correct | 1 | 2 |
*Comparison run on sample data between RAG and KG on 200 questions
When you need scalability and flexibility. KGs can scale more easily as new data is added while maintaining the structure and integrity of the knowledge base. RAG often requires significant retraining and re-indexing of documents.
The best way to leverage the combined power of RAG, KGs, and LLMs always varies with each enterprise and its specific needs. Finding and maintaining the ideal balance enables the enterprise to provide more useful responses that improve both the customer experience and the employee experience.
Business Benefits
Combining these three powerful technologies can improve the customer experience immensely, even if just by providing more accurate, precise, and relevant answers to questions.
More relevant responses
A KG could model relationships between product features (nodes) and customer reviews (nodes). When a customer asks about a specific product, the system can retrieve relevant data points like reviews, specifications, or compatibility (edges) based on the structured graph. This reduces misinformation and enhances the relevance of responses, improving the customer experience.
KGs are also better at resolving multi-hop queries—those that require information from multiple sources. For example, a question like “Which laptops with Intel i7 processors are recommended for gaming under $1,500?” would require a system to traverse various nodes—products, price ranges, and processor specifications—and combine the results to deliver a complete and accurate response.
Better personalization
KG enable businesses to create a detailed, interconnected view of customer preferences, behaviour, and history. For instance, nodes representing a customer’s purchase history, browsing behaviour, and preferences can be linked to product recommendations and marketing content through specific edges like purchased, viewed, or interested in.
This enables the seamless multichannel experiences that are the goal of many marketing initiatives. With KGs, businesses can maintain a consistent understanding of customers across multiple platforms. For example, a support query initiated on social media can be connected to the customer’s order history and past issues using the graph’s interconnected relationships. This provides a unified experience across channels, such as online chat and in-store support, ensuring consistency and enhancing customer loyalty.
Faster, more consistent responses
KGs can link various pieces of data (nodes) such as FAQs, product documents, and troubleshooting guides. When a customer asks a question, the system can traverse these linked nodes to deliver a response faster than traditional methods, as the relationships between nodes are pre-established and easy to query. For instance, an issue with a smartphone’s battery can be connected to battery FAQs, known issues, and repair services, providing faster resolution times.
KG benefits also extend to the employee experience
Smarter knowledge management
KGs help employees, particularly those in customer support and sales, access the right information quickly. For example, nodes representing common issues, product details, and past customer queries can be linked together. When a customer asks a question, employees can easily navigate through these interconnected nodes, finding precise answers without searching multiple databases.
Shorter Training Times
Because KGs organize information in an intuitive, node-based structure, employees can quickly learn to navigate relationships such as product features, customer preferences, and support histories. For instance, a new hire in tech support can easily find how a specific device model is connected to its known issues and solutions, reducing training complexity and time.
Smarter decisions and better collaboration
KGs can centralize and structure knowledge across departments. For instance, marketing can link nodes such as campaign effectiveness and customer feedback, while the product team may link user feedback with feature improvements. These interconnected graphs allow employees to share insights easily and align strategies across departments, breaking down silos.
Reduced Workload on Repetitive Tasks
KGs can automate repetitive queries by linking commonly asked questions to their answers. For example, support tickets (nodes) could be linked to solutions (nodes), and if a similar query arises, the system can automatically retrieve the relevant information without human intervention.
Use cases for RAG, KGs, and LLMs will continue to expand as more enterprises leverage GenAI. Each is powerful in its own right but combining them creates a suite of tools that are far greater than the sum of their parts.
References
- Yu, J., et al. “Knowledge Graph Embedding Based Question Answering.” Proceedings of the 28th International Joint Conference on Artificial Intelligence (2019).
- Ji, S., et al. “A Survey on Knowledge Graphs: Representation, Acquisition, and Applications.” IEEE Transactions on Neural Networks and Learning Systems 33.2 (2022): 494-514.
The telecom industry is in the midst of a technology-driven transformation. Due to rising numbers of devices, increasing broadband and mobile connection speeds, telecom’s technology challenges include implementing IoT, embracing AI, taking advantage of 5G and making their customer gain a competitive advantage. Telcos are focused on:
- Keeping existing customers
- Improving operational efficiencies
- Harnessing the data in their organizations
- Diving deeper into customer insights to improve services
We start with a roadmap using strategies that measure market effectiveness for better conversion rates. Our research into products, segments and behaviors helps us to understand customer profitability and increase margins, followed by an action plan to understand churn and predict CLV.
In this playbook, discover how we’ve helped our clients increase ARPU, drive operational efficiencies, improve NPS scores, conversion rates, revenues and more.
On a global scale, the telecom industry provides crucial services that billions of consumers and businesses rely on every day. Like other industries, telecom has undergone a technology-driven transformation. We’ve helped global telecom’s increase profits and business growth to:
- Increase customer acquisitions by measuring marketing effectiveness for better conversions.
- Generate customer profitability by understanding what products, et al., then attributing cost streams.
- Understand customer churn by predicting customer lifetime value (CLV).
As your partner for success, you leverage our state-of-the-art data science and analytics methodologies and exclusive partnerships.
This playbook, especially curated for the telecom industry demonstrates how we’ve helped our clients increase conversion rates and revenues; reduce churn rates and increase response rates, and more.