- Posted on : March 27, 2025
-
- Industry : Corporate
- Tech Focus : Ignis
- Type: Blog

Fine-tuning LLMs for accuracy and relevance
Natural language processing has been transformed by Large Language Models (LLMs) like GPT and BERT, enabling machines to generate and understand human-like text. Fine-tuning enhances their performance by adapting these models to specific tasks using smaller, domain-specific datasets, enabling them to capture nuanced language patterns. This process improves accuracy and relevance, making LLMs an essential tool for applications like sentiment analysis in the retail industry and chatbot development in customer support.
In this blog, we explore how to choose the right pre-trained model and examine the fine-tuning process. We will review key considerations for fine-tuning that includes data preparation, model selection, parameter adjustments, validation and optimization, deployment and types of fine-tuning.
Choosing the right pre-trained model
First, align the model with task requirements by choosing a pre-trained model that fits the specific needs of the target task or domain of interest. This will ensure that the architecture and input/output specifications support seamless integration for fine-tuning. Additional criteria include:
- Considering model characteristics by evaluating factors such as model size, the nature of the training dataset, and its performance on similar tasks to ensure compatibility with the target application.
- Streamlining fine-tuning by selecting a well-suited pre-trained model that helps optimize the fine-tuning process, enhancing the model's adaptability and effectiveness for the intended application.
- Key fine-tuning parameters and adjust critical parameters like learning rate, number of training epochs, and batch size to control how the model adapts to new task-specific data and achieve optimal performance.
- Selectively freeze early layers of the pre-trained model while fine-tuning the subsequent layers, allowing the model to retain general knowledge and avoid overfitting to the new data.
- Balancing generalization and task-specific learning to help the model maintain its ability to generalize while ensuring the final layers learn task-specific features. This effectively leverages pre-existing knowledge and adapts to the new task.
- Model evaluation assesses a fine-tuned model's performance using a validation set, focusing on metrics like accuracy, loss, precision, and recall.
- Insights for improvement are accomplished by monitoring metrics, which enable identify areas where the model can be improved, ensuring better generalization to new data.
- Optimization with the validation process guides adjustments to fine-tuning parameters, resulting in a more accurate and effective model for the specific task.
The fine-tuning process
The fine-tuning process involves data cleaning, data augmentation, data preparation and data security.
- Data Cleaning and Pre-processing: This step removes noise, handles missing values, and transforms raw data into a model-ready format, ensuring high-quality and relevant data for the task at hand.
- Data Augmentation: Techniques such as generating synthetic data or altering existing data help expand the training dataset, increasing the model's robustness and ability to generalize.
- Impact on Model Performance: Comprehensive data preparation is crucial for fine-tuning, as it directly affects the model's ability to learn effectively, resulting in enhanced performance and accuracy in generating desired outputs.
- Security and Compliance: Most LLMs adhere to GDPR and HIPAA standards, ensuring data security encryption and role-based access control.
Types of fine-tuning
There are two types of fine-tuning to consider—full parameter and parameter-efficient fine tuning. In full parameter fine-tuning, all model weights are updated during training on task-specific data. This approach provides high flexibility and accuracy but requires significant computational resources and copious amount of data.
Parameter-efficient fine-tuning (PEFT) selectively updates a subset of model parameters, using methods like LoRA, QLoRA or adapters. This reduces computational cost and memory usage while still adapting the model to specific tasks effectively. The diagram below depicts the simple PEFT process flow.
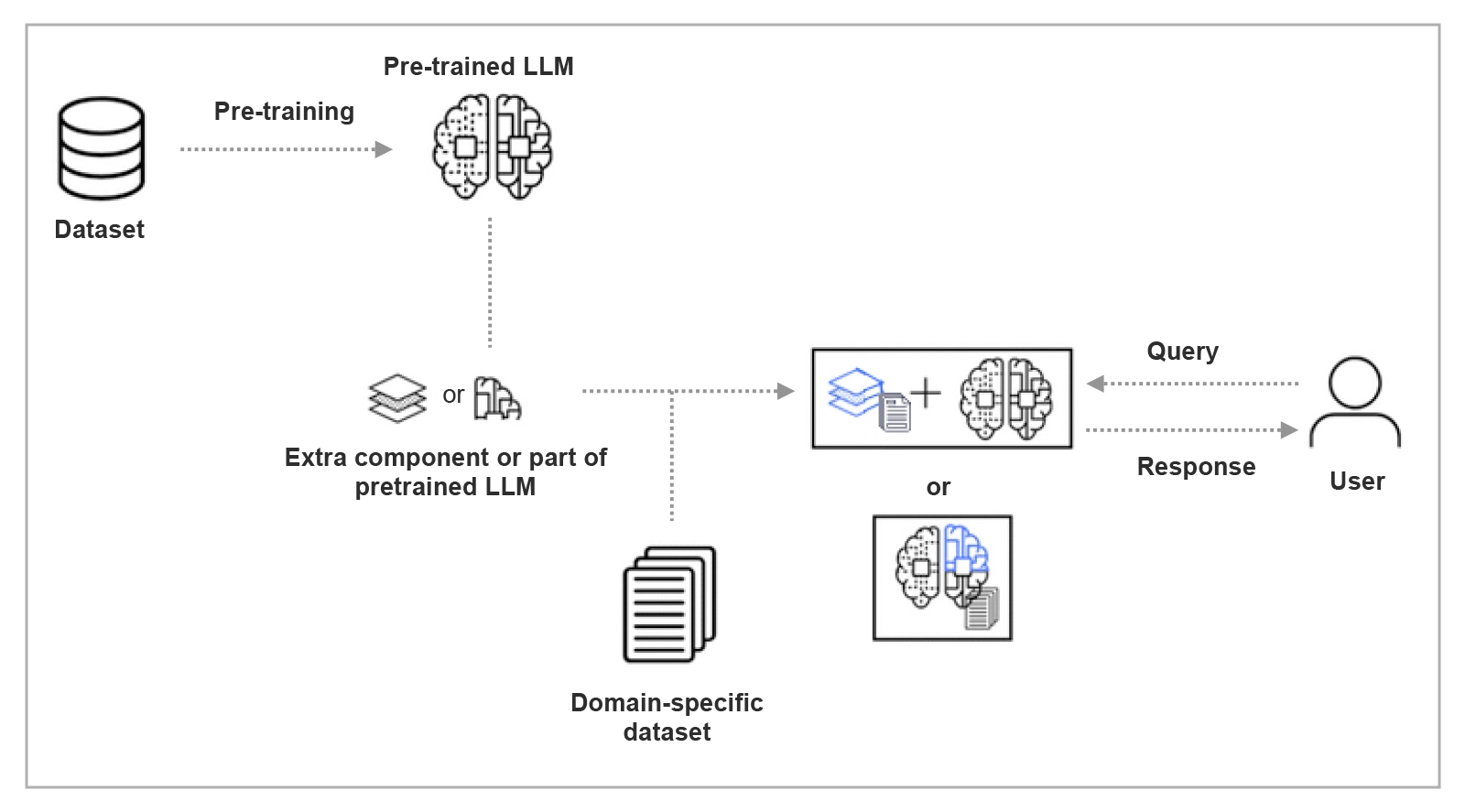
Diagram Showcasing Simple PEFT Process Flow
Conclusion
When it’s time to move the fine-tuned model into a production environment for real world applications, you will need to consider:
- Hardware and software requirements of the deployment environment.
- Integration of the model into existing systems or applications.
- Addressing scalability, real-time performance, and security measures.
A fine-tuned model improves performance, acquires deep expertise in a domain, aligns with business goals and can be customized for specific tasks.
About the Author

Spandan Mitra
Spandan Mitra brings over 11 years of work experience in Data Science. He specializes in creating innovative solutions that drive business transformation. With a deep understanding of AI models and product development, Spandan is dedicated to pushing the boundaries and is enabling the organization to unlock new opportunities through advanced data-driven products. Currently, he is working in the field of Generative AI and has played a key role in shaping up Infogain’s Ignis platform.





