- Posted on : December 9, 2024
-
- Industry : Corporate
- Tech Focus : Data & AI
- Type: Blog

Will a large context window eliminate the need for a RAG approach?
Although the future of GenAI is still very much a blank canvas, senior leaders still need to ensure that they make wise choices regarding how it will and will not be used within their companies. These leaders, especially the ones in roles focused on growth, commerce, innovation and operations, need to fully understand the nuances of the various AI technologies being proposed within their orgs, as well as the long-term benefits and issues that these technologies can bring to the table.
Take retrieval-augmented generation (RAG) for example. Companies have begun to use this rapidly evolving technology to leverage vast amounts of unstructured data, but already there is talk of “RAG killers” that can outperform it.
In natural language processing (NLP), the "context window" is the span of text that an algorithm or model considers while understanding or generating language. New supermassive context windows can accommodate over one million tokens, which drives the idea that they could replace RAG. These context windows expand the range of use cases, but that doesn’t make them RAG killers, nor do executives need to choose between one or the other as they chart the futures of their companies.
Context windows include a certain number of words or tokens surrounding a target word to capture relationships and meaning within the text. For example, in models like Word2Vec, the context window helps in understanding semantic relationships by analysing words before and after a target word. In transformers like GPT-3, the context window is the portion of text the model uses to generate or predict the next token, directly impacting the coherence and relevance of its output.
Figure 1. Context Window
RAG is a hybrid model that combines the strengths of retrieval-based and generation-based approaches. In essence, it retrieves relevant information from a large corpus or database (like a search engine) and then uses that information to generate a coherent and contextually appropriate response or piece of text. This allows for more accurate and informed responses, particularly in scenarios where the model might not have all the required information within its training data alone.
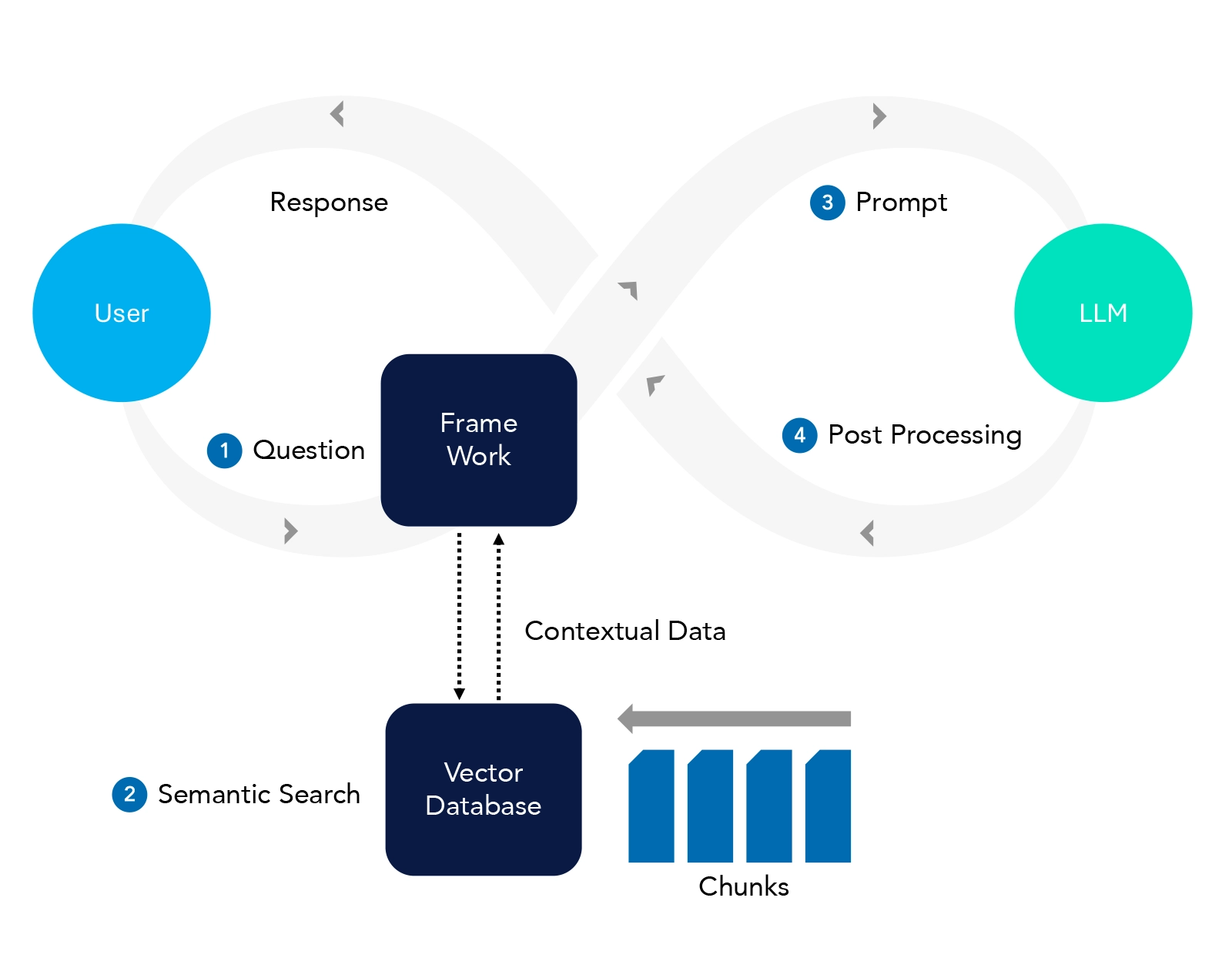
Figure 2. RAG Architecture
What are the key differences?
As with any technology, the ideal choice for a specific enterprise depends on the structure of that enterprise, its legacy stack, ability to support new technologies, and dozens of other variables.
Here are some of the key differences between RAG and long context windows.
| Feature | Long Context Window | RAG Model |
| Capacity | Can handle up to thousands of tokens | Efficient data handling by retrieving smaller text chunks |
| Perplexity | Lower perplexity due to broader context awareness, reducing ambiguity | Efficiently reduces perplexity by narrowing down to relevant information |
| Coherence | High coherence across contents, preserving narrative flow | May struggle with coherence across diverse retrieved sources |
| Dependence | Dependence on input context | Dependent on external databases or knowledge sources |
| Diversity | Limited by the scope of pre-trained data | Better handling of diverse information from multiple sources |
| Precision | General high-level precision, not detail-oriented | High precision in answering specific queries accurately |
| Consistency | Strong narrative consistency across long texts | Inconsistent context due to varied retrieved sources |
| Context Relevance | Maintains relevant context throughout the document | May vary, depending on the quality of retrieved documents |
| Current Information | Limited to knowledge up to the training cut-off | Better at incorporating the most recent data |
| Memory Intensive | Requires significant GPU memory for large context processing | Distributed load between retrieval and generation processes |
| Latency | Higher latency due to handling extensive textual data | Faster inference balanced by retrieval workload |
| Optimization | Requires advanced hardware optimization for effective use | Lower hardware requirements compared to LCW |
| Adaptation | Limited adaptability due to fixed pre-trained data | Highly adaptable, quickly integrates new data |
| Customization | Less customizable without extensive re-training on new data | Easily customized for domain-specific needs via retrieval tuning |
| Environment Compatibility | Challenging integration in diverse environments without extensive tuning | Supports frequent updates with minimal re-training |
| Ideal For | Document summarization, in-depth analysis, thesis writing | Real-time Q&A, chatbots, and dynamic content retrieval |
| Less Suited For | Real-time information retrieval, dynamic environments | Long-form content generation without retrieval refresh |
| Content Generation | Ideal for generating comprehensive, unbroken narratives | Limited by the need for real-time retrieval |
| Training Time | Longer training times due to heavy data processing requirements | Faster training if pre-established retrieval corpus is available |
| Inference Time | Slower inference with large contexts, impacting responsiveness | Faster inference balanced by retrieval workload |
| Algorithmic Complexity | High complexity making it difficult to optimize | Relatively simpler algorithms with modular retrieval and generation components |
| Integration | Complex integration due to hardware and optimization needs | Easier integration with existing systems due to modularity |
| Maintenance | High maintenance with frequent updates required | Lower maintenance mainly focusing on retrieval database updates |
| Deployment | Challenging deployment in resource-constrained environments | Simpler deployment with standard hardware support |
| Cost | High, requires extensive training and updating | Minimal, no training required |
| Data Timeliness | Data can quickly become outdated | Data retrieved on demand, ensuring currency |
| Transparency | Low, unclear how data influences outcomes | High, shows retrieved documents |
| Scalability | Limited, scaling up involves significant resources | High, easily integrates with various data sources |
| Performance | Performance can degrade with larger context sizes | Selective data retrieval enhances performance |
| Adaptability | Requires retraining for significant adaptations | Can be tailored to specific tasks without retraining |
It’s always a balance.
Both large context window and RAG systems have their own pros and cons, but large context LLMs are not always RAG killers.
The Long Context Window model excels in maintaining extensive context and coherence, suitable for comprehensive document processing but demands higher computational resources.
- Document Summarization and Analysis – A long context window model can read and summarize entire documents, research papers, legal contracts, or technical manuals while maintaining overall context and coherence throughout.
- Thesis Writing and Long-Form Content Generation – Long context window models are ideal for generating cohesive long-form content, such as research papers, white papers, or blog posts, where maintaining the flow and narrative consistency across multiple sections is critical.
- Legal Document Review and Compliance – When reviewing lengthy legal documents or contracts, these models can ensure that no details are lost by understanding context across tens of thousands of words.
In contrast, the RAG model is optimal for real-time information retrieval, offering flexibility and precision with lower resource use, making it ideal for dynamic querying applications like chatbots and Q&A systems.
- Real-Time Q&A Systems and Chatbots – RAG models are highly effective for building chatbots that retrieve up-to-date information from external databases and provide precise, real-time answers based on current or domain-specific data.
- Dynamic Product Recommendations – In e-commerce or financial services, RAG models can provide personalized product recommendations by retrieving data about customer behavior and preferences from multiple sources.
- Customer Support – RAG models can enhance customer service by pulling from various knowledge bases, product documents, and FAQs, to provide accurate and relevant responses without the need for extensive retraining.
A hybrid approach (Long Context Window LLM + RAG) is the need of the hour, and can make applications more robust and efficient.
- Enhanced Flexibility – The hybrid approach combines the extensive context awareness of long window models with the dynamic retrieval capability of RAG models, enabling applications to seamlessly handle both structured and unstructured information at scale.
- Improved Precision and Contextual Understanding – By retrieving the most relevant information in real-time through RAG while maintaining overall coherence through a long context window, the hybrid model enhances accuracy in responses, particularly for complex, multi-faceted queries.
- Resource Efficiency – The hybrid model can offload some of the computationally intensive processes (like full document parsing) to RAG systems, making it possible to scale large AI models while optimizing hardware and resource usage.
As enterprise leaders consider the future of AI within their companies and organizations, both RAG and large context windows offer significant benefits. Wise leaders will understand the ramifications of each technology, then choose how to combine and balance them based on their vision for the future of their enterprise.
About the Author

Spandan Mitra
Spandan Mitra brings over 11 years of work experience in Data Science. He specializes in creating innovative solutions that drive business transformation. With a deep understanding of AI models and product development, Spandan is dedicated to pushing the boundaries and is enabling the organization to unlock new opportunities through advanced data-driven products. Currently, he is working in the field of Generative AI and has played a key role in shaping up Infogain’s Ignis platform.




