- Posted on : October 28, 2024
-
- Industry : Corporate
- Studio : Data & AI
- Type: Blog
Every day, more enterprises leverage GenAI to enable self-service, streamline call-center operations, and otherwise improve the experiences they offer customers and employees. But questions arise about how to optimize the relationships between retrieval-augmented generation (RAG), knowledge graphs (KG), and large language models (LLM). Combining these three components in the smartest ways enables enterprise tools to generate more accurate and useful responses that can improve the experience for all users.
- A knowledge graph is a collection of nodes and edges that represent entities or concepts, and their relationships, such as facts, properties, or categories. It is used to query or infer factual information about different entities or concepts, based on their node and edge attributes.
- Retrieval augmented generation combines retrieval of relevant documents with generative models to produce more informed and accurate responses. RAG uses retrieval mechanisms to find pertinent information from a large corpus, which is then fed into the generative model to enhance its output.
- A large language model generates human-like text based on the input it receives. LLMs are trained on vast amounts of data to understand and generate natural language and can perform a wide range of language-related tasks.
Augmenting RAG with KGs leverages the structured nature of KGs to enhance traditional vector search retrieval methods, which improves the depth and contextuality of the information it retrieves. KGs organize data as nodes and relationships representing entities and their connections, which can be queried to infer factual information. Combining KGs with RAG enables LLMs to generate more accurate and contextually enriched responses.
Implementing a KG-RAG approach involves several steps.
Knowledge Graph Curation
- Data Collection: Start with the ingestion of unstructured data from desired knowledge base.
- Entity Extraction: Identify and extract entities (people, places, events) from the data.
- Relationship Identification: Determine the relationships between entities to form the edges of the graph.
- Graph Building: Construct the knowledge graph using the identified entities and relationships.
- Store Embeddings in Graph Database: Generate embeddings from the knowledge graph and store these embeddings in a graph database for efficient retrieval
RAG Integration
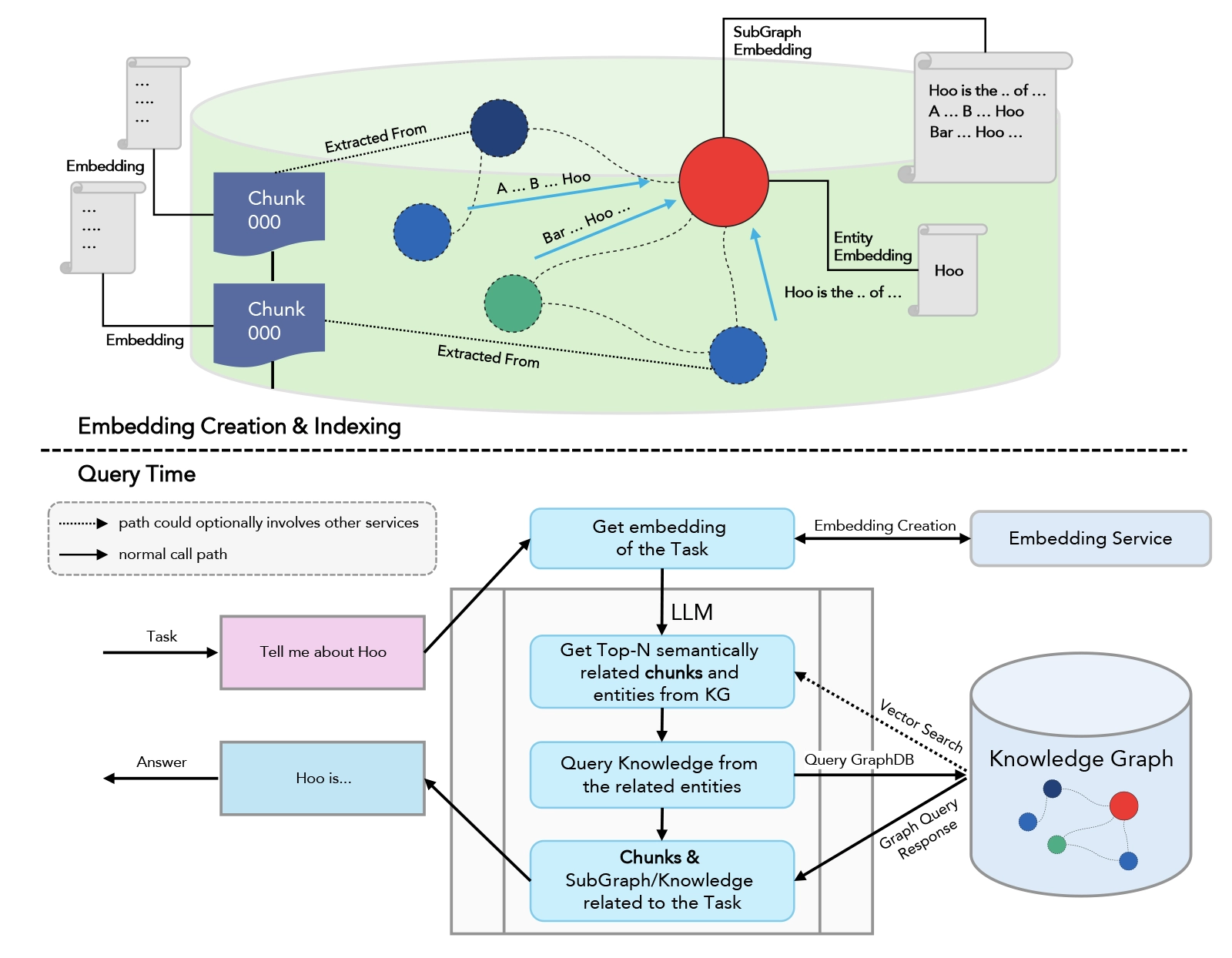
- Document Retrieval: Use the Knowledge graph vector db to retrieve relevant documents or information chunks that the LLM can use. Similar chunks corresponding to questions are retrieved using similarity algorithms like cosine or Euclidean distance. These chunks are fed into the LLM along with the query.
- Contextual Generation: The LLM uses the retrieved information to generate responses that are contextually accurate and enriched with domain-specific knowledge.
System Optimization
- Fine-Tuning: Adjust the LLM using domain-specific data to improve response accuracy.
- Graph Updates: Continuously update the KG with new data to keep the information current and relevant.
- Efficient Prompt Engineering: Develop and optimize prompts to guide the LLM effectively, ensuring the model generates relevant and precise responses based on the retrieved information and the user's query.
Flow diagram
When should you choose KG over RAG?
When you typically have complex queries. KGs support more diverse and complex queries than vector databases, handling logical operators and intricate relationships. This capability helps LLMs generate more diverse and interesting text. Examples of complex queries where KG outperforms RAG include
- One Page vs. Multiple Pages of the Same Document vs. Multiple Documents: KGs work well in scenarios where information is spread across multiple chunks (pages). They can efficiently handle queries requiring information from different sections of a single document or multiple documents by connecting related entities
- Multi-hop Questions: KGs support multi-hop question-answering tasks, where a single question is broken down into multiple sub-questions. For example, answering "Did any former OpenAI employees start their own company?" involves first identifying former employees and then determining if any of them founded a company. KGs enable the retrieval of interconnected information, facilitating accurate and complete answers.
When you need to enhance reasoning and inference. KGs enable reasoning and inference, providing indirect information through entity relationships. This enhances the logical and consistent nature of the text generated by the LLM.
When you need to reduce hallucinations. KGs provide more precise and specific information than vector databases, which reduces hallucinations in LLMs. Vector databases indicate the similarity or relatedness between two entities or concepts, whereas KGs enable a better understanding of the relationship between them. For instance, a KG can tell you that “Eiffel Tower” is a landmark in “Paris”, while a vector database can only indicate how similar the two concepts are.
The KG approach effectively retrieves and synthesizes information dispersed across multiple PDFs. For example, it can handle cases where an objective answer (e.g., yes/no) is in one document and the reasoning is in another PDF. This reduces wrong answers (False Positive) which is common in Vector db
Vector databases give similar matches just on text similarity which increases False Negative cases and hallucinations. Knowledge graphs capture contextual and causality relationships, so they don’t produce answers that seem similar based purely on text similarity.
| Metric | RAG | KG |
|---|---|---|
| Correct Response | 153 | 167 |
| Incorrect Response | 46 | 31 |
| Partially Correct | 1 | 2 |
*Comparison run on sample data between RAG and KG on 200 questions
When you need scalability and flexibility. KGs can scale more easily as new data is added while maintaining the structure and integrity of the knowledge base. RAG often requires significant retraining and re-indexing of documents.
The best way to leverage the combined power of RAG, KGs, and LLMs always varies with each enterprise and its specific needs. Finding and maintaining the ideal balance enables the enterprise to provide more useful responses that improve both the customer experience and the employee experience.
Business Benefits
Combining these three powerful technologies can improve the customer experience immensely, even if just by providing more accurate, precise, and relevant answers to questions.
More relevant responses
A KG could model relationships between product features (nodes) and customer reviews (nodes). When a customer asks about a specific product, the system can retrieve relevant data points like reviews, specifications, or compatibility (edges) based on the structured graph. This reduces misinformation and enhances the relevance of responses, improving the customer experience.
KGs are also better at resolving multi-hop queries—those that require information from multiple sources. For example, a question like "Which laptops with Intel i7 processors are recommended for gaming under $1,500?" would require a system to traverse various nodes—products, price ranges, and processor specifications—and combine the results to deliver a complete and accurate response.
Better personalization
KG enable businesses to create a detailed, interconnected view of customer preferences, behaviour, and history. For instance, nodes representing a customer's purchase history, browsing behaviour, and preferences can be linked to product recommendations and marketing content through specific edges like purchased, viewed, or interested in.
This enables the seamless multichannel experiences that are the goal of many marketing initiatives. With KGs, businesses can maintain a consistent understanding of customers across multiple platforms. For example, a support query initiated on social media can be connected to the customer’s order history and past issues using the graph’s interconnected relationships. This provides a unified experience across channels, such as online chat and in-store support, ensuring consistency and enhancing customer loyalty.
Faster, more consistent responses
KGs can link various pieces of data (nodes) such as FAQs, product documents, and troubleshooting guides. When a customer asks a question, the system can traverse these linked nodes to deliver a response faster than traditional methods, as the relationships between nodes are pre-established and easy to query. For instance, an issue with a smartphone's battery can be connected to battery FAQs, known issues, and repair services, providing faster resolution times.
KG benefits also extend to the employee experience
Smarter knowledge management
KGs help employees, particularly those in customer support and sales, access the right information quickly. For example, nodes representing common issues, product details, and past customer queries can be linked together. When a customer asks a question, employees can easily navigate through these interconnected nodes, finding precise answers without searching multiple databases.
Shorter Training Times
Because KGs organize information in an intuitive, node-based structure, employees can quickly learn to navigate relationships such as product features, customer preferences, and support histories. For instance, a new hire in tech support can easily find how a specific device model is connected to its known issues and solutions, reducing training complexity and time.
Smarter decisions and better collaboration
KGs can centralize and structure knowledge across departments. For instance, marketing can link nodes such as campaign effectiveness and customer feedback, while the product team may link user feedback with feature improvements. These interconnected graphs allow employees to share insights easily and align strategies across departments, breaking down silos.
Reduced Workload on Repetitive Tasks
KGs can automate repetitive queries by linking commonly asked questions to their answers. For example, support tickets (nodes) could be linked to solutions (nodes), and if a similar query arises, the system can automatically retrieve the relevant information without human intervention.
Use cases for RAG, KGs, and LLMs will continue to expand as more enterprises leverage GenAI. Each is powerful in its own right but combining them creates a suite of tools that are far greater than the sum of their parts.
References
- Yu, J., et al. "Knowledge Graph Embedding Based Question Answering." Proceedings of the 28th International Joint Conference on Artificial Intelligence (2019).
- Ji, S., et al. "A Survey on Knowledge Graphs: Representation, Acquisition, and Applications." IEEE Transactions on Neural Networks and Learning Systems 33.2 (2022): 494-514.
About the Author

Sachin Kaushik
Sachin Kaushik is a senior consultant at Infogain, he is a seasoned data scientist with extensive experience in developing machine learning models for the financial and retail sectors. His interests encompass natural language processing, deep learning, and GEN-AI solutions. Notable projects include a GPT-4 based chatbot that addresses user queries with streaming and memory capabilities, along with a question-answering system built on RAG architecture, utilizing GPT-4 and vector databases. He also conducts trainings on prompt engineering and LLM applications





