- Posted on : October 16, 2017
-
- Industry : Digital and High Technology
- Type: Blog

The application of advanced analytics for application software testing
What could be
A recent IBM commercial features a repairman checking in with an office building concierge for an appointment to fix an elevator. There’s nothing wrong with the elevator, but you want to fix it? the concierge asks. Right, nods the repairman. Who sent you? he probes. New guy says the repairman. What new guy? asks? Watson, he quips.
Not very long ago, the idea of proactive maintenance based on large-scale predictive analytics would have been banned to the domain of a ‘boil the ocean’ strategy– too much heavy lifting for the expected output. Now, with IoT devices such as elevators, streaming operational telemetry to data pools and lakes, the combined performance of all networked elevators can be statistically analyzed for likely points of failure. This intelligence is then harnessed to define maintenance plans designed to eliminate faults before they occur and, equally importantly, define plans for areas that don’t need maintained because they carry no current risk of failure.
The analogy to the application quality assurance world would be intelligence that would allow us to pinpoint exactly what to test and what not to test. The result would be better software being delivered to our customers more quickly at a much lower cost. Unfortunately, the reality in the software development world today is still very much counter to this scenario.
The Legacy Model – Defining test scope by ‘gut feel’
The idea of transitioning from a shotgun to rifle approach in test plan definition is not new. Risk-based testing models and tools like SAP’s Solution Manager with Business Process Change Analyzer have been around for many years. Both offer benefits over large-scale, random-regression sweeps, but neither offer a solution that aligns with our IBM Watson example. Risk-based testing is either too loose or cumbersome, and SolMan and solutions of their genre are specific only to the package software they support.
Since neither adapt very well, or at all, to custom software development, our findings in the market is that most organizations still stick to a heavy-handed approach entailing pre-release runs of often excessively large regression test repositories. Some of these are automated, but many still skew heavily to costly manual efforts. Making things worse, test managers often make the hard decision of which test suite subset to execute because of fixed time, resource or cost constraints. Ultimately, and we hear this often in the marketplace, decisions are ‘gut feel’ at best, or even ‘random’ in the worst case scenario.
What has changed – technical advances that enable a new approach
So what has changed to enable a new approach? Very much, to be frank. For starters, there is data. The myriad tools currently supporting the development of software span the spectrum from requirements management, user story and functional designs to test cases and defect, build and release management. Post deployment, incident management tools and end-use feedback provide a treasure trove of data sources.
To help us manage this structured and unstructured data, solutions like Hadoop, and its ecosystem of tools, provide the ability to process and model large sets of disparate data and offer data analysts with a comprehensive view of the SDLC.
To make sense of this data, we have seen massive leaps in the power and cost effectiveness of statistical analysis tools from both commercial and open-source worlds. Companies like SPSS and SAS combine best-in-class tools for data analysis and provide in-memory processing integrated with Hadoop data pools for large- scale needs. Open source tool sets, such as Knime Analytics Platform and R, offer similar, albeit scaled-down, functionality, but allow data scientists to extract similar intelligence at a must lower price point. The ultimate goal is the ability to run as many statistical models across the in-scope data set in as little time as possible. And where earlier tools required frequent analyst intervention for each model run, modern tools enable the simultaneous execution of linear, logistic, polynomial, and other regression models at the touch of a button. As a result, the selection of optimal statistical fit takes minutes instead of hours.
Predictive Analytics for Quality
Think this is all still conceptual? Think again. At Infogain we have successfully carried out pilots with key clients and the results have been staggering. By combining these individual tools and proprietary methods, we have created a solution called Predictive Analytics for Quality. Although its construction is complex, its mission is simple. Leverage the wealth of data generated every day in the software development process to help us define what to test.
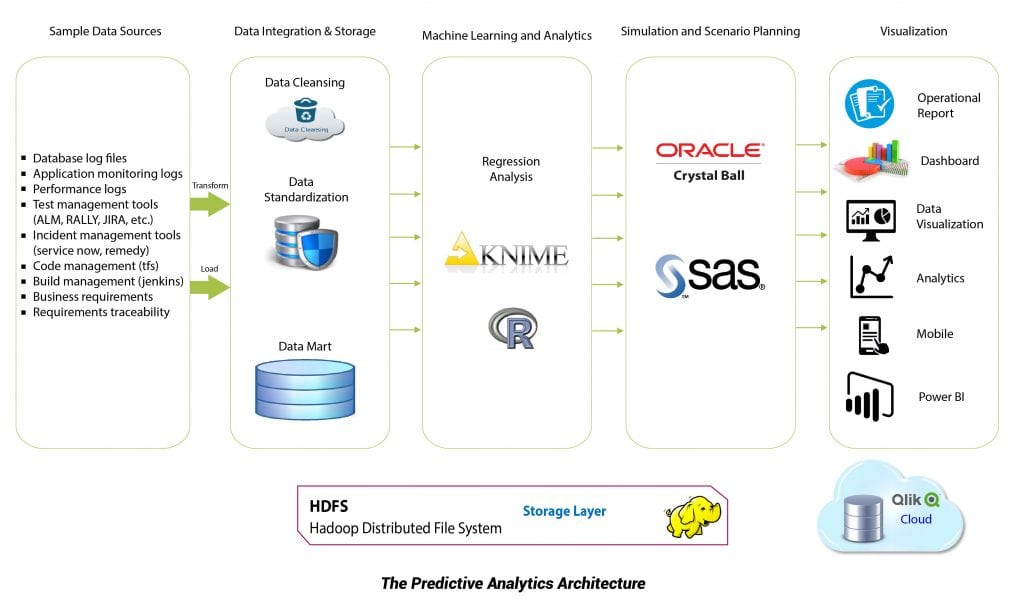
If we consider the master metadata associated with software development and quality management, a great deal of structured and unstructured data is generated in each release. Data types include production logs, defects logs, user stories, incident tickets, test cases, RICEF libraries, etc. The core challenge of applying predictive analytics to quality assurance is how to best analyze this data and draw meaningful insights. By creating a platform to extract, classify, cluster and store this data, combined with analysis tools to detect trend patterns, and visualization tools to create meaningful information from these patterns, we are able to predict the probabilities of failure for isolated new or existing software components. This allows us to train our testing focus on these risk areas.
In our multiple proofs of concept, we have conducted backcasting exercises against historical data using our predictive analytics solution, and have been able to identify points of failure with an accuracy of 98%. This intelligence has been applied to regression scenarios where clients are able to reduce two-week executions of tens of thousands of randomly selected test suites to a testing volume of less than a thousand with no significant impact on quality. The end result is less effort to release code of the same quality in a fraction of the time.
Conclusion — A Continuous Quality Engine
This is not where the story ends. When combined with our Unified Automation Platform; a framework of open source tools; specialized methods and custom developed modules for test management; reporting and integration enabling progressive or in-sprint automation, we are able to deliver on an elusive goal. We’re able to augment one of the market’s best test automation solutions that answers the question ‘how to I test?’ with an analytics solution that answers ‘what do I test?’.
Completing the picture are machine learning algorithms that essentially create a solution that removes human intervention from the process—in essence a continuous quality engine.
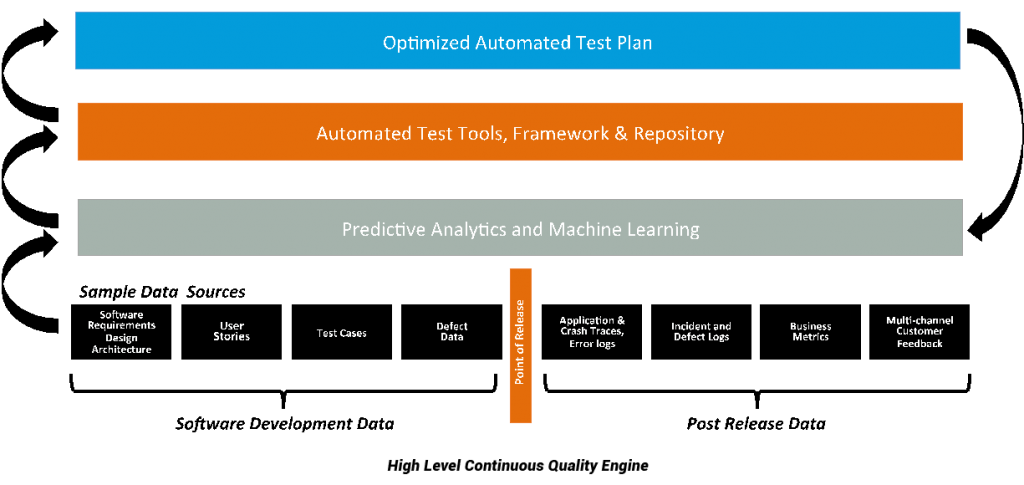
With each successive automated testing run, new data is extracted from source systems and stored in the data management layer of the Predicative Analytics module. Machine Learning then recalibrates the statistical model for a newly optimized fit, and provides updated intelligence on potential points of failure in the system under test. This intelligence allows the definition of a new Optimized Automated Test Plan that is then executed. And the cycle continues.
Often the laggard in the world of quality, software quality assurance is on the cusp of an incredible leap forward. Understanding that brains, not brawn, is the best approach to enable this shift, Infogain has embraced the reality of fully automated quality processes and fully intends to help lead the way for our clients.
Authored by Robb La Velle, VP and Global Leader of the Business Assurance group for Infogain Corp
News Originally Posted on: VAR INDIA





